Kompilering og kørsel af R fra kommandolinjen
De to måder at køre R-programmer på er: et R-script, som er meget udbredt og er mest foretrukket, og det andet er R CMD BATCH, det er ikke en almindeligt anvendt kommando. Vi kan ringe til dem direkte fra kommandolinjen eller enhver anden jobplanlægning.
Du kan tænkes at kalde disse kommandoer fra en shell, der er indbygget i IDE, og i dag kommer RStudio IDE med værktøjer, der forbedrer eller administrerer R-scriptet og R CMD BATCH-funktionerne.
kilde () funktion inde i R er et godt alternativ til at bruge kommandolinjen. Denne funktion kan også kalde et script, men for at bruge denne funktion skal du være inde i R-miljøet.
R Indbyggede datasæt på sprog
For at liste de datasæt, der er indbygget med R, skal du bruge kommandoen data (), derefter finde det, du vil have, og bruge navnet på datasættet i data () -funktionen. Ligesom data (funktionsnavn).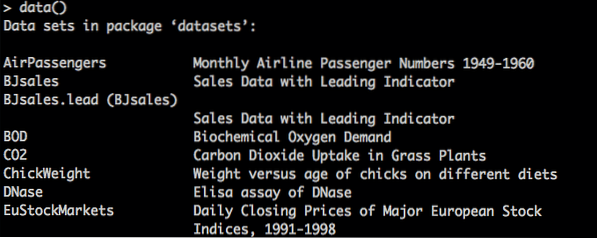
Vis datasæt i R
Spørgsmålstegnet (?) kunne bruges til at bede om hjælp til datasæt.
For at tjekke for alt brug resumé ().
Plot () er også en funktion, der bruges til at plotte grafer.
Lad os oprette et test script og køre det. skab p1.R fil og gem den hjemmekatalog med følgende indhold:
Kodeeksempel:
# Enkel hej verdenskode i R print ("Hello World!") print (" LinuxHint ") print (5 + 6) 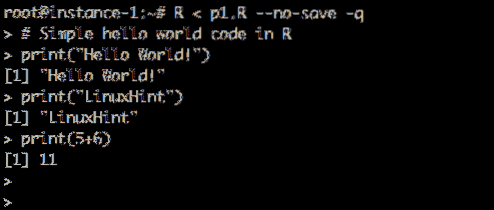
Kører Hello World
R datarammer
Til lagring af data i tabeller bruger vi en struktur i R kaldet a Dataramme. Det bruges til at liste vektorer af samme længde. For eksempel er følgende variable nm en dataramme, der indeholder tre vektorer x, y, z:
x = c (2, 3, 5) y = c ("aa", "bb", "cc") z = c (SAND, FALSK, SAND) # nm er en dataramme nm = data.ramme (n, s, b) Der er et koncept kaldet IndbyggetDatarammer i R også. mtcars er en sådan indbygget dataramme i R, som vi vil bruge som et eksempel til vores bedre forståelse. Se koden nedenfor:
> mtcars mpg cyl disp hp drat wt… Mazda RX4 21.0 6 160 110 3.90 2.62… bus RX4 Wag 21.0 6 160 110 3.90 2.88… Datsun 710 22.8 4 108 93 3.85 2.32 ..
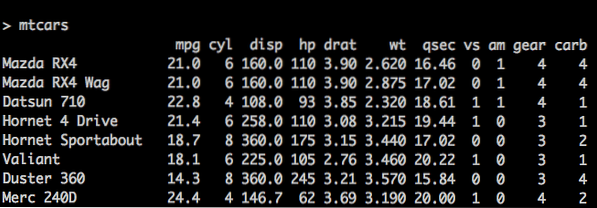
mtcars bulitin dataframe
Overskriften er den øverste linje i tabellen, der indeholder kolonnenavnene. Datarækker doneres af hver vandret linje; hver linje starter med navnet på rækken og derefter efterfulgt af de faktiske data. Datalementet i en række betegnes som en celle.
Vi ville indtaste række- og kolonnekoordinaterne i en enkelt firkantet parentes '[]' operator for at hente data i en celle. For at adskille koordinaterne bruger vi et komma. Ordren er vigtig. Koordinaten begynder med række og derefter komma og slutter derefter med kolonnen. Celleværdi på 2nd række og 1St kolonne er angivet som:
> mtcars [2, 2] [1] 6
Vi kan også bruge række- og kolonnenavn i stedet for koordinater:
> mtcars ["Bus RX4", "mpg"] [1] 6
nrow-funktion bruges til at finde antallet af rækker i datarammen.
> nrow (mtcars) # antal datarækker [1] 32
ncol-funktionen bruges til at finde antallet af kolonner i en dataramme.
> ncol (mtcars) # antal kolonner [1] 11
R Programmering af sløjfer
Under nogle betingelser bruger vi sløjfer, når vi vil automatisere en del af koden, eller vi vil gentage en række instruktioner.
Til sløjfe i R
Hvis vi ønsker at udskrive disse års information mere end én gang.
print (indsæt ("Året er", 2000)) "Året er 2000" print (indsæt ("Året er", 2001)) "Året er 2001" print (indsæt ("Året er", 2002) ) "Året er 2002" print (indsæt ("Året er", 2003)) "Året er 2003" print (indsæt ("Året er", 2004)) "Året er 2004" print (indsæt (" Året er ", 2005))" Året er 2005 " I stedet for at gentage vores erklæring igen og igen, hvis vi bruger til loop det vil være meget lettere for os. Sådan her:
for (år i c (2000,2001,2002,2003,2004,2005)) print (indsæt ("Året er", år)) "Året er 2000" "Året er 2001" "Året er 2002 "" Året er 2003 "" Året er 2004 "" Året er 2005 " Mens Loop i R
mens (udtryk) udsagn
Hvis resultatet af udtrykket er SAND, indtastes sløjfekroppen. Sætningerne inde i sløjfen udføres, og strømmen vender tilbage for at vurdere udtrykket igen. Sløjfen gentager sig, indtil udtrykket evalueres til FALSK, i hvilket tilfælde sløjfen kommer ud.
Eksempel på while Loop:
# i initialiseres oprindeligt til 0 i = 0 mens (i<5) print (i) i=i+1 Output: 0 1 2 3 4
I ovenstående mens loop er udtrykket jeg<5som måler til SAND siden 0 er mindre end 5. Derfor udføres sløjfekroppen, og jeg er output og inkrementeret. Det er vigtigt at øge jeg inde i løkken, så det på en eller anden måde vil opfylde betingelsen på et eller andet tidspunkt. I den næste sløjfe er værdien af jeg er 1, og sløjfen fortsætter. Det gentager sig indtil jeg er lig med 5, når betingelsen 5<5 reached loop will give FALSE and the while loop will exit.
R Funktioner
At oprette en fungere vi bruger direktivets funktion (). Specifikt er de R-objekter i klassen fungere.
f <- function() ##some piece of instructions
Især kan funktioner overføres til andre funktioner, da argumenter og funktioner kan indlejres, så du kan bestemme en funktion inde i en anden funktion.
Funktioner kan valgfrit have nogle navngivne argumenter, der har standardværdier. Hvis du ikke ønsker en standardværdi, kan du indstille dens værdi til NULL.
Nogle fakta om R-funktionsargumenter:
- De argumenter, der er tilladt i funktionsdefinitionen, er de formelle argumenter
- Formalsfunktionen kunne give en liste over alle de formelle argumenter for en funktion
- Ikke alle funktionsopkald i R bruger alle de formelle argumenter
- Funktionsargumenter kan have standardværdier, eller de mangler muligvis
#Definerer en funktion: f <- function (x, y = 1, z = 2, s= NULL)
Oprettelse af en logistisk regressionsmodel med indbygget datasæt
Det glm () funktion bruges i R til at passe til den logistiske regression. glm () -funktionen svarer til lm (), men glm () har nogle yderligere parametre. Dens format ser sådan ud:
glm (X ~ Z1 + Z2 + Z3, familie = binomial (link = ”logit”), data = mydata)
X er afhængig af værdierne Z1, Z2 og Z3. Hvilket betyder, at Z1, Z2 og Z3 er uafhængige variabler, og X er afhængig Funktion involverer ekstra parameterfamilie, og den har værdi binomial (link = "logit"), der betyder, at linkfunktion er logit, og sandsynlighedsfordelingen af regressionsmodel er binomial.
Antag, at vi har et eksempel på en studerende, hvor han får adgang på baggrund af to eksamensresultater. Datasættet indeholder følgende emner:
- resultat _1- Resultat-1 score
- resultat _2- Resultat -2 score
- optaget- 1 hvis optaget eller 0 hvis ikke optaget
I dette eksempel har vi to værdier 1, hvis en studerende fik adgang og 0, hvis han ikke fik adgang. Vi er nødt til at generere en model for at forudsige, at den studerende fik adgang eller ej,. For et givet problem betragtes optaget som en afhængig variabel, exam_1 og exam_2 betragtes som uafhængige variabler. For den model er vores R-kode angivet
> Model_1<-glm(admitted ~ result_1 +result_2, family = binomial("logit"), data=data) Lad os antage, at vi har to resultater af den studerende. Resultat-1 65% og resultat-2 90%, nu forudsiger vi, at den studerende får adgang eller ikke for at estimere sandsynligheden for, at den studerende får adgang, vores R-kode er som nedenfor:
> in_frame<-data.frame(result_1=65,result_2=90) >forudsig (Model_1, in_frame, type = "respons") Output: 0.9894302
Ovenstående output viser os sandsynligheden mellem 0 og 1. Hvis det er mindre end 0.5 betyder det, at studerende ikke fik adgang. I denne tilstand vil den være FALSK. Hvis den er større end 0.5, vil betingelsen blive betragtet som SAND, hvilket betyder, at den studerende har fået adgang. Vi er nødt til at bruge runde () -funktionen til at forudsige sandsynligheden mellem 0 og 1.
R-kode for det er som vist nedenfor:
> runde (forudsig (Model_1, in_frame, type = "respons")) [/ code] Output: 1
En studerende får adgang, da output er 1. Desuden kan vi også forudsige andre observationer på samme måde.
Brug af logistisk regressionsmodel (scoring) med nye data
Når det er nødvendigt, kan vi gemme modellen i en fil. R-kode for vores togmodel vil se sådan ud:
modellen <- glm(my_formula, family=binomial(link='logit'),data=model_set)
Denne model kan gemmes med:
gem (fil = "filnavn", fil_filen)
Du kan bruge filen efter at have gemt den ved at bruge den fred i R-koden:
load (file = "filnavn")
For at anvende modellen til nye data kan du bruge denne linje i en kode:
model_set $ pred <- predict(the_model, newdata=model_set, type="response")
BEMÆRK: Model_set kan ikke tildeles nogen variabel. For at indlæse en model bruger vi funktionsbelastningen (). Nye observationer ændrer ikke noget i modellen. Modellen forbliver den samme. Vi bruger den gamle model til at forudsige de nye data for ikke at ændre noget i modellen.
Konklusion
Jeg håber, du har set, hvordan R-programmering fungerer på en grundlæggende måde, og hvordan du hurtigt kan komme i gang med maskinindlæring og statistik kodning med R.


