For at komme i gang skal du have MySQL installeret på dit system med dets hjælpeprogrammer: MySQL-arbejdsbænk og kommandolinjeklientshell. Derefter skal du have nogle data eller værdier i dine databasetabeller som duplikater. Lad os udforske dette med nogle eksempler. Først og fremmest skal du åbne din kommandolinjeklientshell fra din desktop-proceslinje og skrive din MySQL-adgangskode efter anmodning.

Vi har fundet forskellige metoder til at finde duplikeret i en tabel. Se på dem en efter en.
Søg efter duplikater i en enkelt kolonne
Først skal du vide om syntaksen for den forespørgsel, der bruges til at kontrollere og tælle dubletter for en enkelt kolonne.
>> VÆLG kol. TÆLL (kol.) FRA tabel GRUPPE FOR kolHer er forklaringen på ovenstående forespørgsel:
- Kolonne: Navnet på den kolonne, der skal kontrolleres.
- TÆLLE(): funktionen bruges til at tælle mange duplikerede værdier.
- GRUPP AF: klausulen, der bruges til at gruppere alle rækker efter den pågældende kolonne.
Vi har oprettet en ny tabel kaldet 'dyr' i vores MySQL-database 'data' med dobbelte værdier. Det har seks kolonner med forskellige værdier, f.eks.g., id, navn, art, køn, alder og pris, der giver oplysninger om forskellige kæledyr. Når vi kalder denne tabel ved hjælp af SELECT-forespørgslen, får vi nedenstående output på vores MySQL-kommandolinjeklientshell.
>> VÆLG * FRA data.dyr;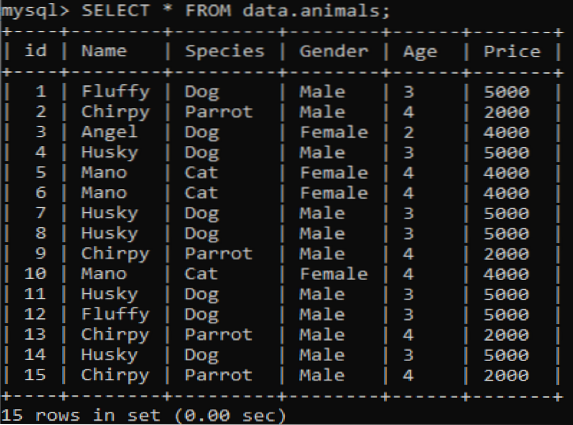
Nu vil vi forsøge at finde de overflødige og gentagne værdier fra ovenstående tabel ved at bruge TÆLLE- og GROUP BY-udtrykket i SELECT-forespørgslen. Denne forespørgsel tæller navnene på kæledyr, der er placeret mindre end 3 gange i tabellen. Derefter viser det disse navne som nedenfor.
>> VÆLG Navn TÆLL (navn) FRA data.dyr GRUPPER PÅ Navn HAR TÆLLER (Navn) < 3;
Brug af den samme forespørgsel til at få forskellige resultater, mens du ændrer COUNT-nummeret for kæledyrsnavne som vist nedenfor.
>> VÆLG Navn TÆLL (navn) FRA data.dyr GRUPPER PÅ Navn MED TÆLLING (Navn)> 3;
For at få resultater for i alt 3 duplikatværdier for navne på kæledyr som vist nedenfor.
>> VÆLG Navn TÆLL (navn) FRA data.dyr GRUPPER PÅ Navn HAR TÆLLER (Navn) = 3;
Søg efter duplikater i flere kolonner
Syntaks for forespørgslen for at kontrollere eller tælle duplikater for flere kolonner er som følger:
>> VÆLG col1, COUNT (col1), col2, COUNT (col2) FRA tabel GRUPPE FOR col1, col2 HAR COUNT (col1)> 1 OG COUNT (col2)> 1;Her er forklaringen på ovenstående forespørgsel:
- col1, col2: navnet på de kolonner, der skal kontrolleres.
- TÆLLE(): funktionen bruges til at tælle flere duplikerede værdier.
- GRUPP AF: klausulen, der bruges til at gruppere alle rækker efter den specifikke kolonne.
Vi har brugt den samme tabel kaldet 'dyr' med dobbelte værdier. Vi fik nedenstående output, mens vi brugte ovenstående forespørgsel til kontrol af de duplikerede værdier i flere kolonner. Vi har kontrolleret og talt de dobbelte værdier for kolonner Køn og pris, mens de er grupperet efter kolonnen Pris. Det viser kæledyrs køn og deres priser, der findes i tabellen som duplikater, ikke mere end 5.
>> VÆLG Køn, TÆLLING (Køn), Pris, TÆLLING (Pris) FRA data.dyr GRUPP FOR PRIS HAVT TÆLLER (Pris) < 5 AND COUNT(Gender) < 5;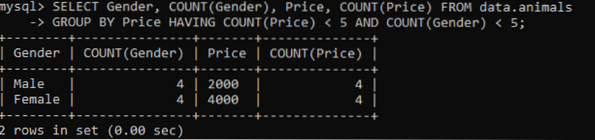
Søg efter duplikater i enkeltbord ved hjælp af INNER JOIN
Her er den grundlæggende syntaks til at finde dubletter i en enkelt tabel:
>> VÆLG col1, col2, tabel.col FRA tabel INNRE JOIN (VÆLG col FRA tabel GRUPPE VED kol. HAVTÆLL (col1)> 1) temp ON tabel.col = temp.col;Her er fortællingen om overheadforespørgslen:
- Col: navnet på den kolonne, der skal kontrolleres og vælges til duplikater.
- Midlertidig: nøgleord for at anvende indre sammenføjning i en kolonne.
- Bord: navnet på den tabel, der skal kontrolleres.
Vi har en ny tabel, 'order2' med duplikerede værdier i kolonnen OrderNo som vist nedenfor.
>> VÆLG * FRA data.ordre2;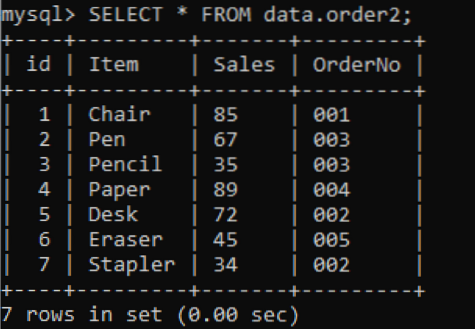
Vi vælger tre kolonner: Vare, Salg, Ordrenr., Der skal vises i output. Mens kolonnen OrderNo bruges til at kontrollere dubletter. Den indre sammenføjning vælger de værdier eller rækker, der har værdierne for varer mere end en i en tabel. Efter udførelse får vi resultaterne nedenfor.
>> VÆLG vare, salg, ordre2.OrderNo FROM data.order2 INNER JOIN (VÆLG OrderNr FRA data.ordre2 GRUPPER Efter ordre nr. HAR TÆLLER (vare)> 1) temp ON ordre2.OrderNo = temp.Ordre nummer;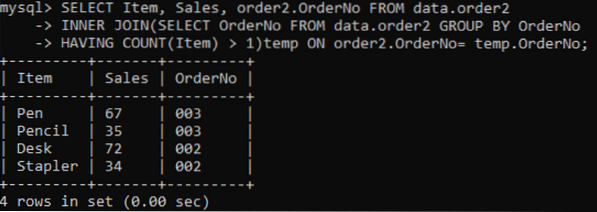
Søg efter duplikater i flere tabeller ved hjælp af INNER JOIN
Her er den forenklede syntaks til at finde dubletter i flere tabeller:
>> VÆLG kolonne FRA tabel1 INDRE FORENEDE tabel2 PÅ tabel1.col = tabel2.col;Her er beskrivelsen af overheadforespørgslen:
- kol: navnet på de kolonner, der skal kontrolleres og vælges.
- INDRE MEDLEM: den funktion, der bruges til at slutte sig til to tabeller.
- PÅ: bruges til at forbinde to tabeller i henhold til de angivne kolonner.
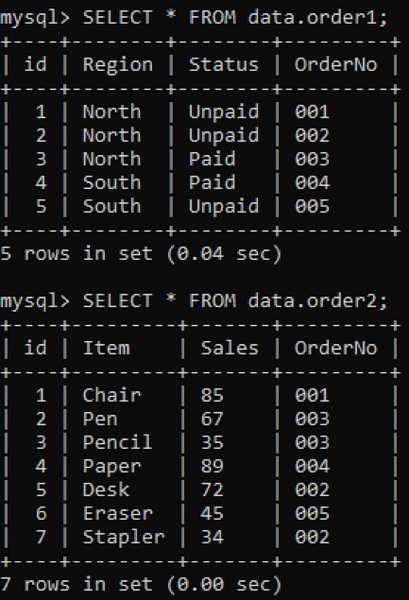
Vi har to tabeller, 'order1' og 'order2', i vores database med kolonnen 'OrderNo' i begge som vist nedenfor.
Vi bruger INNER-sammenføjningen til at kombinere duplikaterne af to tabeller i henhold til en specificeret kolonne. INNER JOIN-klausulen får alle data fra begge tabeller ved at slutte sig til dem, og ON-klausulen vil relatere de samme kolonner fra begge tabeller, e.g., Ordre nummer.
>> VÆLG * FRA data.rækkefølge1 INNER JOIN data.ordre2 TIL ordre1.OrderNo = ordre2.Ordre nummer;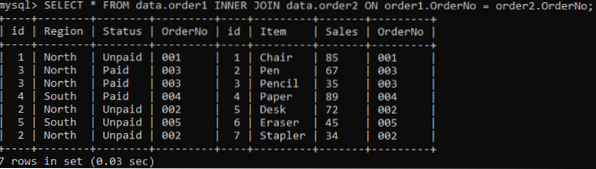
For at få de bestemte kolonner i et output, prøv nedenstående kommando:
>> VÆLG region, status, vare, salg fra data.rækkefølge1 INNER JOIN data.ordre2 TIL ordre1.OrderNo = ordre2.Ordre nummer;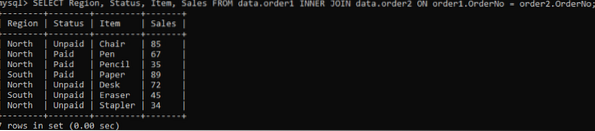
Konklusion
Vi kunne nu søge efter flere kopier i en eller flere tabeller med MySQL-oplysninger og genkende funktionen GROUP BY, COUNT og INNER JOIN. Sørg for, at du har bygget tabellerne korrekt, og også at de rigtige kolonner er valgt.


