Dette er en opfølgningsartikel til de to foregående [2,3]. Indtil videre indlæste vi indekserede data i Apache Solr-lageret og forespurgte data om det. Nu vil du lære at forbinde det relationelle databasestyringssystem PostgreSQL [4] til Apache Solr og at foretage en søgning i det ved hjælp af Solr's muligheder. Dette gør det nødvendigt at udføre flere trin beskrevet nedenfor mere detaljeret - opsætning af PostgreSQL, forberedelse af en datastruktur i en PostgreSQL-database og tilslutning af PostgreSQL til Apache Solr og udførelse af vores søgning.
Trin 1: Opsætning af PostgreSQL
Om PostgreSQL - en kort info
PostgreSQL er et genialt objektrelationelt databasesystem. Det har været tilgængeligt til brug og har gennemgået en aktiv udvikling i over 30 år nu. Det stammer fra University of California, hvor det ses som efterfølgeren til Ingres [7].
Fra starten er den tilgængelig under open source (GPL), gratis at bruge, ændre og distribuere. Det er meget brugt og meget populært i branchen. PostgreSQL blev oprindeligt designet til kun at køre på UNIX / Linux-systemer og blev senere designet til at køre på andre systemer som Microsoft Windows, Solaris og BSD. Den nuværende udvikling af PostgreSQL udføres over hele verden af adskillige frivillige.
PostgreSQL opsætning
Hvis det ikke er gjort endnu, skal du installere PostgreSQL-serveren og klienten lokalt, for eksempel på Debian GNU / Linux som beskrevet nedenfor ved hjælp af apt. To artikler beskæftiger sig med PostgreSQL - Yunis Saids artikel [5] diskuterer opsætningen på Ubuntu. Alligevel skraber han kun overfladen, mens min tidligere artikel fokuserer på kombinationen af PostgreSQL med GIS-udvidelsen PostGIS [6]. Beskrivelsen her opsummerer alle de trin, vi har brug for til denne særlige opsætning.
# apt install postgresql-13 postgresql-client-13Kontroller derefter, at PostgreSQL kører ved hjælp af kommandoen pg_isready. Dette er et værktøj, der er en del af PostgreSQL-pakken.
# pg_ er allerede klar/ var / run / postgresql: 5432 - Forbindelser accepteres
Outputtet ovenfor viser, at PostgreSQL er klar og venter på indgående forbindelser på port 5432. Medmindre andet er angivet, er dette standardkonfigurationen. Det næste trin er at indstille adgangskoden til UNIX-brugeren Postgres:
# passwd PostgresHusk, at PostgreSQL har sin egen brugerdatabase, mens den administrative PostgreSQL-bruger Postgres endnu ikke har en adgangskode. Det foregående trin skal også gøres for PostgreSQL-brugeren Postgres:
# su - Postgres$ psql -c "ALTER USER Postgres WITH PASSWORD 'password';"
For nemheds skyld er den valgte adgangskode kun en adgangskode og skal erstattes af en mere sikker adgangskodesætning på andre systemer end test. Kommandoen ovenfor ændrer den interne brugertabel i PostgreSQL. Vær opmærksom på de forskellige anførselstegn - adgangskoden i enkelte anførselstegn og SQL-forespørgslen i dobbelt anførselstegn for at forhindre, at shell-fortolker evaluerer kommandoen på den forkerte måde. Tilføj også et semikolon efter SQL-forespørgslen før de dobbelte citater i slutningen af kommandoen.
Derefter skal du af administrative årsager oprette forbindelse til PostgreSQL som bruger-Postgres med den tidligere oprettede adgangskode. Kommandoen kaldes psql:
$ psqlForbindelse fra Apache Solr til PostgreSQL-databasen sker som brugeren. Så lad os tilføje PostgreSQL-brugerens solr og indstille en tilsvarende adgangskodesolr for ham på én gang:
$ OPRET BRUGER solr MED PASSWD 'solr';For nemheds skyld er den valgte adgangskode bare solr og skal erstattes af en mere sikker adgangskodesætning på systemer, der er i produktion.
Trin 2: Forberedelse af en datastruktur
For at gemme og hente data er der brug for en tilsvarende database. Kommandoen nedenfor opretter en database med biler, der tilhører brugerens solr og vil blive brugt senere.
$ CREATE DATABASE biler MED EJER = solr;Opret derefter forbindelse til de nyoprettede databasebiler som bruger solr. Indstillingen -d (kort mulighed for -dbname) definerer databasenavnet og -U (kort mulighed for -brugernavn) navnet på PostgreSQL-brugeren.
$ psql -d biler -U solrEn tom database er ikke nyttig, men strukturerede tabeller med indhold gør det. Opret strukturen på bordbilerne som følger:
$ CREATE TABLE biler (id int,
lav varchar (100),
model varchar (100),
beskrivelse varchar (100),
farve varchar (50),
pris int
);
Tabellen biler indeholder seks datafelter - id (heltal), mærke (en streng af længde 100), model (en streng af længde 100), beskrivelse (en streng af længde 100), farve (en streng af længde 50) og pris (heltal). For at få nogle eksempeldata tilføj følgende værdier til tabelbiler som SQL-sætninger:
$ INDSÆT I biler (id, mærke, model, beskrivelse, farve, pris)VÆRDIER (1, 'BMW', 'X5', 'Cool bil', 'grå', 45000);
$ INDSÆT I biler (id, mærke, model, beskrivelse, farve, pris)
VÆRDIER (2, 'Audi', 'Quattro', 'racerbil', 'hvid', 30000);
Resultatet er to poster, der repræsenterer en grå BMW X5, der koster USD 45.000, beskrevet som en sej bil, og en hvid racerbil Audi Quattro, der koster USD 30000.
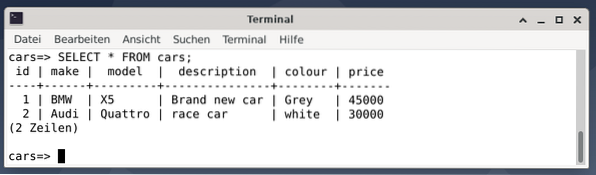
Gå derefter ud af PostgreSQL-konsollen ved hjælp af \ q, eller afslut.
$ \ qTrin 3: Tilslutning af PostgreSQL med Apache Solr
PostgreSQL og Apache Solrs forbindelse er baseret på to stykker software - en Java-driver til PostgreSQL kaldet Java Database Connectivity (JDBC) driver og en udvidelse til Solr-serverkonfigurationen. JDBC-driveren tilføjer en Java-grænseflade til PostgreSQL, og den ekstra post i Solr-konfigurationen fortæller Solr, hvordan man opretter forbindelse til PostgreSQL ved hjælp af JDBC-driveren.
Tilføjelse af JDBC-driveren udføres som brugerrod som følger og installerer JDBC-driveren fra Debian-pakkelageret:
# apt-get install libpostgresql-jdbc-javaPå Apache Solr-siden skal der også eksistere en tilsvarende node. Hvis ikke gjort endnu, som UNIX-brugeren solr, skal du oprette nodebiler som følger:
$ bin / solr oprette -c bilerUdvid derefter Solr-konfigurationen til den nyoprettede node. Føj nedenstående linjer til filen / var / solr / data / cars / conf / solrconfig.xml:
db-data-config.xmlOpret desuden en fil / var / solr / data / biler / conf / data-config.xml, og gem følgende indhold i den:
Linjerne ovenfor svarer til de tidligere indstillinger og definerer JDBC-driveren, angiv porten 5432, der skal oprette forbindelse til PostgreSQL DBMS som brugeren solr med den tilsvarende adgangskode, og indstil SQL-forespørgslen, der skal udføres fra PostgreSQL. For enkelheds skyld er det en SELECT-sætning, der fanger hele indholdet af tabellen.
Genstart derefter Solr-serveren for at aktivere dine ændringer. Som brugerrod udfører følgende kommando:
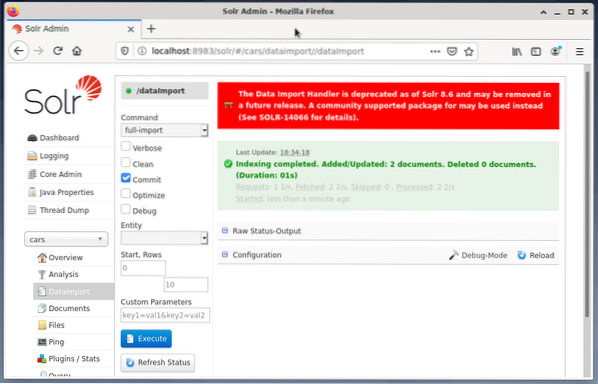
# systemctl genstart solrDet sidste trin er importen af dataene, f.eks. Ved hjælp af Solr-webgrænsefladen. Noden markeringsfeltet vælger nodebiler, derefter fra Node-menuen under posten Dataimport efterfulgt af markeringen af fuld-import fra Kommando-menuen lige til den. Til sidst skal du trykke på knappen Udfør. Figuren nedenfor viser, at Solr med succes har indekseret dataene.
Trin 4: Forespørgsel om data fra DBMS
Den foregående artikel [3] beskæftiger sig med forespørgsel på data i detaljer, hentning af resultatet og valg af det ønskede outputformat - CSV, XML eller JSON. Forespørgsel om data sker på samme måde som det, du har lært før, og ingen forskel er synlig for brugeren. Solr udfører alt arbejdet bag kulisserne og kommunikerer med PostgreSQL DBMS forbundet som defineret i den valgte Solr-kerne eller klynge.
Brugen af Solr ændres ikke, og forespørgsler kan sendes via Solr-administratorgrænsefladen eller ved hjælp af curl eller wget på kommandolinjen. Du sender en Get-anmodning med en bestemt URL til Solr-serveren (forespørgsel, opdatering eller sletning). Solr behandler anmodningen ved hjælp af DBMS som en lagerenhed og returnerer resultatet af anmodningen. Derefter skal du behandle svaret lokalt.
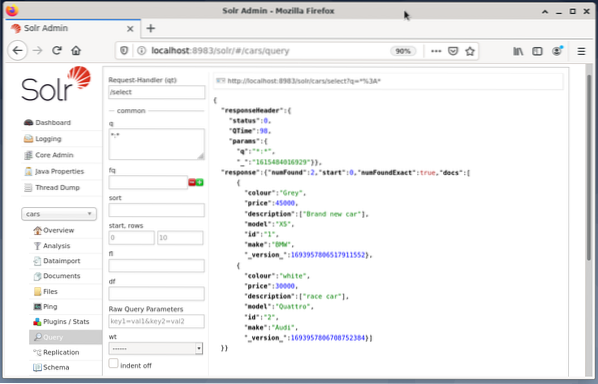
Eksemplet nedenfor viser output fra forespørgslen “/ select?q = *. * ”I JSON-format i Solr-administratorgrænsefladen. Dataene hentes fra databasebiler, som vi oprettede tidligere.
Konklusion
Denne artikel viser, hvordan du forespørger om en PostgreSQL-database fra Apache Solr og forklarer den tilsvarende opsætning. I den næste del af denne serie lærer du, hvordan du kombinerer flere Solr-noder i en Solr-klynge.
Om forfatterne
Jacqui Kabeta er miljøforkæmper, ivrig forsker, træner og mentor. I flere afrikanske lande har hun arbejdet i it-industrien og NGO-miljøer.
Frank Hofmann er it-udvikler, træner og forfatter og foretrækker at arbejde fra Berlin, Genève og Cape Town. Medforfatter til Debian Package Management Book tilgængelig fra dpmb.org
Links og referencer
- [1] Apache Solr, https: // lucene.apache.org / solr /
- [2] Frank Hofmann og Jacqui Kabeta: Introduktion til Apache Solr. Del 1, https: // linuxhint.com / apache-solr-setup-a-node /
- [3] Frank Hofmann og Jacqui Kabeta: Introduktion til Apache Solr. Forespørgsel om data. Del 2, http: // linuxhint.com
- [4] PostgreSQL, https: // www.postgresql.org /
- [5] Younis Said: Sådan installeres og opsættes PostgreSQL-database på Ubuntu 20.04, https: // linuxhint.com / install_postgresql_-ubuntu /
- [6] Frank Hofmann: Opsætning af PostgreSQL med PostGIS på Debian GNU / Linux 10, https: // linuxhint.com / setup_postgis_debian_postgres /
- [7] Ingres, Wikipedia, https: // da.wikipedia.org / wiki / Ingres_ (database)


