Dette er en opfølgningsartikel til den forrige. Vi vil dække, hvordan man forfiner forespørgslen, formulerer mere komplekse søgekriterier med forskellige parametre og forstår Apache Solr-forespørgselssidens forskellige webformularer. Vi vil også diskutere, hvordan man efterbehandler søgeresultatet ved hjælp af forskellige outputformater såsom XML, CSV og JSON.
Forespørgsel på Apache Solr
Apache Solr er designet som en webapplikation og -tjeneste, der kører i baggrunden. Resultatet er, at ethvert klientapplikation kan kommunikere med Solr ved at sende forespørgsler til det (fokus i denne artikel), manipulere dokumentkernen ved at tilføje, opdatere og slette indekserede data og optimere kernedata. Der er to muligheder - via dashboard / web-interface eller ved hjælp af en API ved at sende en tilsvarende anmodning.
Det er almindeligt at bruge første mulighed til testformål og ikke til regelmæssig adgang. Figuren nedenfor viser instrumentbrættet fra Apache Solr Administration-brugergrænsefladen med de forskellige forespørgselsformularer i webbrowseren Firefox.
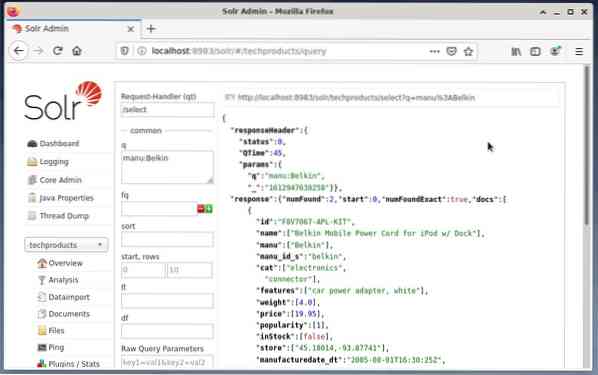
Vælg først menuen "Forespørgsel" fra menuen under kernevalgfeltet. Derefter viser instrumentbrættet flere indtastningsfelter som følger:
- Anmodningshåndterer (qt):
Definer, hvilken type anmodning du vil sende til Solr. Du kan vælge mellem standardhåndteringsanmodningerne “/ select” (forespørgsel indekseret data), “/ opdatering” (opdater indekseret data) og “/ slet” (fjern de angivne indekserede data) eller en selvdefineret. - Forespørgselshændelse (q):
Definer hvilke feltnavne og værdier der skal vælges. - Filtrer forespørgsler (fq):
Begræns supersæt af dokumenter, der kan returneres uden at påvirke dokumentets score. - Sorter rækkefølge (sorter):
Definer sorteringsrækkefølgen for forespørgselsresultaterne til enten stigende eller faldende - Output-vindue (start og rækker):
Begræns output til de angivne elementer - Feltliste (fl):
Begrænser oplysningerne i et forespørgselssvar til en specificeret liste over felter. - Outputformat (wt):
Definer det ønskede outputformat. Standardværdien er JSON.
Ved at klikke på knappen Udfør forespørgsel køres den ønskede anmodning. Se praktiske eksempler nedenfor.
Som den anden mulighed, du kan sende en anmodning ved hjælp af en API. Dette er en HTTP-anmodning, der kan sendes til Apache Solr af enhver applikation. Solr behandler anmodningen og returnerer et svar. Et specielt tilfælde af dette er at oprette forbindelse til Apache Solr via Java API. Dette er outsourcet til et separat projekt kaldet SolrJ [7] - en Java API uden at kræve en HTTP-forbindelse.
Forespørgselssyntaks
Forespørgselssyntaks beskrives bedst i [3] og [5]. De forskellige parameternavne svarer direkte til navnene på indtastningsfelterne i ovenstående formularer. Tabellen nedenfor viser dem plus praktiske eksempler.
Forespørgselsparametreindeks
| Parameter | Beskrivelse | Eksempel |
|---|---|---|
| q | Den primære forespørgselsparameter for Apache Solr - feltnavne og værdier. Deres lighedsscorer dokumenterer udtryk i denne parameter. | Id: 5 biler: * adilla * *: X5 |
| fq | Begræns resultatsættet til de superset-dokumenter, der matcher filteret, for eksempel defineret via funktionsområde forespørgselsparser | model id, model |
| Start | Forskydninger for sideresultater (begynder). Standardværdien for denne parameter er 0. | 5 |
| rækker | Forskydninger for sideresultater (slut). Værdien af denne parameter er som standard 10 | 15 |
| sortere | Det specificerer listen over felter adskilt af kommaer, baseret på hvilke forespørgselsresultaterne skal sorteres | model asc |
| fl | Den specificerer listen over de felter, der skal returneres for alle dokumenterne i resultatsættet | model id, model |
| vægt | Denne parameter repræsenterer den type svarforfatter, vi ønskede at se resultatet. Værdien af dette er JSON som standard. | json xml |
Søgninger foretages via HTTP GET-anmodning med forespørgselsstrengen i q-parameteren. Eksemplerne nedenfor vil afklare, hvordan dette fungerer. I brug er curl for at sende forespørgslen til Solr, der er installeret lokalt.
- Hent alle datasæt fra kernebilernes krølle http: // localhost: 8983 / solr / biler / forespørgsel?q = *: *
- Hent alle datasæt fra kernebiler, der har en id på 5 curl http: // localhost: 8983 / solr / cars / query?q = id: 5
- Hent feltmodellen fra alle datasæt til kernebiler
Mulighed 1 (med undsluppet og): krølle http: // localhost: 8983 / solr / biler / forespørgsel?q = id: * \ & fl = modelMulighed 2 (forespørgsel i enkelt kryds):
curl 'http: // localhost: 8983 / solr / cars / query?q = id: * & fl = model ' - Hent alle datasæt af kernebiler sorteret efter pris i faldende rækkefølge, og indtast kun felterne fabrikat, model og pris (version i enkelt kryds): curl http: // localhost: 8983 / solr / cars / query -d '
q = *: * &
sorter = prisbeskrivelse &
fl = fabrikat, model, pris ' - Hent de første fem datasæt af kernebiler sorteret efter pris i faldende rækkefølge, og kun udfyld felterne fabrikat, model og pris (version i enkelt kryds): krølle http: // localhost: 8983 / solr / biler / forespørgsel - d '
q = *: * &
rækker = 5 &
sorter = prisbeskrivelse &
fl = mærke, model, pris ' - Hent de første fem datasæt af kernebiler sorteret efter pris i faldende rækkefølge, og output kun felterne fabrikat, model og pris plus dens relevans score, kun (version i enkelt kryds): krølle http: // localhost: 8983 / solr / biler / forespørgsel -d '
q = *: * &
rækker = 5 &
sorter = prisbeskrivelse &
fl = fabrikat, model, pris, score ' - Returner alle lagrede felter såvel som relevansscore: curl http: // localhost: 8983 / solr / cars / query -d '
q = *: * &
fl = *, score '
Desuden kan du definere din egen anmodningshåndterer til at sende de valgfri anmodningsparametre til forespørgselsparseren for at kontrollere, hvilke oplysninger der returneres.
Forespørgselsparsere
Apache Solr bruger en såkaldt query parser - en komponent, der oversætter din søgestreng til specifikke instruktioner til søgemaskinen. En forespørgselsparser står mellem dig og det dokument, du søger efter.
Solr leveres med en række parsertyper, der adskiller sig i den måde, en indsendt forespørgsel håndteres på. Standard Query Parser fungerer godt til strukturerede forespørgsler, men er mindre tolerant over for syntaksfejl. Samtidig er både DisMax og Extended DisMax Query Parser optimeret til naturlige sproglignende forespørgsler. De er designet til at behandle enkle sætninger indtastet af brugerne og til at søge efter individuelle udtryk på tværs af flere felter ved hjælp af forskellige vægtninger.
Desuden tilbyder Solr også såkaldte Function Queries, der gør det muligt at kombinere en funktion med en forespørgsel for at generere en specifik relevans score. Disse parsere hedder Function Query Parser og Function Range Query Parser. Eksemplet nedenfor viser sidstnævnte til at vælge alle datasættene til “bmw” (gemt i datafeltets fabrikat) med modellerne fra 318 til 323:
krølle http: // localhost: 8983 / solr / biler / forespørgsel -d 'q = mærke: bmw &
fq = model: [318 TIL 323] '
Efterbehandling af resultater
Afsendelse af forespørgsler til Apache Solr er en del, men efterbehandling af søgeresultatet fra den anden. For det første kan du vælge mellem forskellige svarformater - fra JSON til XML, CSV og et forenklet Ruby-format. Du skal blot angive den tilsvarende wt-parameter i en forespørgsel. Kodeeksemplet nedenfor demonstrerer dette for at hente datasættet i CSV-format for alle elementerne ved hjælp af krølle med escaped &:
krølle http: // localhost: 8983 / solr / biler / forespørgsel?q = id: 5 \ & wt = csvOutputtet er en komma-adskilt liste som følger:

For kun at modtage resultatet som XML-data, men de to outputfelter fremstiller og modelleres, skal du køre følgende forespørgsel:
krølle http: // localhost: 8983 / solr / biler / forespørgsel?q = *: * \ & fl = fabrikat, model \ & wt = xmlOutputtet er forskelligt og indeholder både svarhovedet og det aktuelle svar:
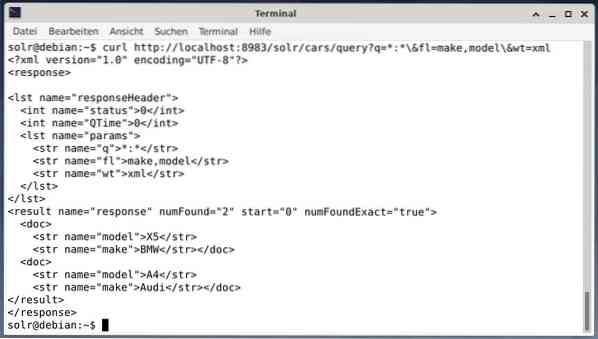
Wget udskriver simpelthen de modtagne data på stdout. Dette giver dig mulighed for at efterbehandle svaret ved hjælp af standardkommandolinjeværktøjer. For at nævne nogle få indeholder dette jq [9] til JSON, xsltproc, xidel, xmlstarlet [10] til XML samt csvkit [11] til CSV-format.
Konklusion
Denne artikel viser forskellige måder at sende forespørgsler til Apache Solr og forklarer, hvordan man behandler søgeresultatet. I den næste del lærer du, hvordan du bruger Apache Solr til at søge i PostgreSQL, et relationsdatabasehåndteringssystem.
Om forfatterne
Jacqui Kabeta er miljøforkæmper, ivrig forsker, træner og mentor. I flere afrikanske lande har hun arbejdet i it-industrien og NGO-miljøer.
Frank Hofmann er it-udvikler, træner og forfatter og foretrækker at arbejde fra Berlin, Genève og Cape Town. Medforfatter til Debian Package Management Book tilgængelig fra dpmb.org
Links og referencer
- [1] Apache Solr, https: // lucene.apache.org / solr /
- [2] Frank Hofmann og Jacqui Kabeta: Introduktion til Apache Solr. Del 1, http: // linuxhint.com
- [3] Yonik Seelay: Solr Query Syntax, http: // yonik.com / solr / forespørgsel-syntaks /
- [4] Yonik Seelay: Solr Tutorial, http: // yonik.com / solr-tutorial /
- [5] Apache Solr: Forespørgsel om data, Tutorialspoint, https: // www.tutorialspoint.com / apache_solr / apache_solr_querying_data.htm
- [6] Lucene, https: // lucene.apache.org /
- [7] SolrJ, https: // lucene.apache.org / solr / guide / 8_8 / using-solrj.html
- [8] krølle, https: // krølle.se /
- [9] jq, https: // github.com / stedolan / jq
- [10] xmlstarlet, http: // xmlstar.sourceforge.net/
- [11] csvkit, https: // csvkit.readthedocs.io / da / seneste /


