Installation af Tesseract OCR i Linux
Tesseract OCR er tilgængelig som standard på de fleste Linux-distributioner. Du kan installere det i Ubuntu ved hjælp af kommandoen nedenfor:
$ sudo apt installere tesseract-ocrDetaljerede instruktioner til andre distributioner er tilgængelige her. Selvom Tesseract OCR som standard er tilgængelig i lagre af mange Linux-distributioner, anbefales det at installere den nyeste version fra ovennævnte link for forbedret nøjagtighed og parsing.
Installation af support til yderligere sprog i Tesseract OCR
Tesseract OCR inkluderer understøttelse af registrering af tekst på over 100 sprog. Du får dog kun support til detektering af tekst på engelsk med standardinstallationen i Ubuntu. For at tilføje support til parsing af yderligere sprog i Ubuntu skal du køre en kommando i følgende format:
$ sudo apt installerer tesseract-ocr-hinKommandoen ovenfor tilføjer understøttelse af det hindi-sprog til Tesseract OCR. Nogle gange kan du få bedre nøjagtighed og resultater ved at installere support til sprogskripter. For eksempel, installation og brug af tesseract-pakken til Devanagari-scriptet "tesseract-ocr-script-deva" gav mig meget mere nøjagtige resultater end at bruge pakken "tesseract-ocr-hin".
I Ubuntu kan du finde korrekte pakkenavne til alle sprog og scripts ved at køre kommandoen nedenfor:
$ apt-cache søgning tesseract-Når du har identificeret det korrekte pakkenavn, der skal installeres, skal du erstatte strengen “tesseract-ocr-hin” med den i den første kommando, der er angivet ovenfor.
Brug af Tesseract OCR til at udtrække tekst fra billeder
Lad os tage et eksempel på et billede vist nedenfor (taget fra Wikipedia-siden til Linux):

For at udtrække tekst fra billedet ovenfor skal du køre en kommando i følgende format:
$ tesseract capture.png output -l engAt køre kommandoen ovenfor giver følgende output:
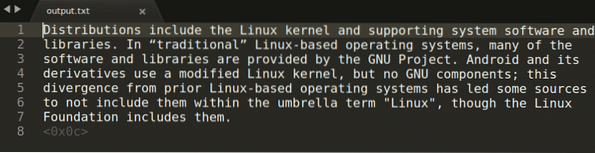
I kommandoen ovenfor “fang.png ”henviser til det billede, hvorfra du vil udtrække teksten. Det fangede output lagres derefter i “output.txt-fil. Du kan ændre sproget ved at erstatte “eng” -argumentet med dit eget valg. For at se alle gyldige sprog skal du køre kommandoen nedenfor:
$ tesseract - liste-langsDet viser forkortelseskoder for alle sprog, der understøttes af Tesseract OCR på dit system. Som standard viser det kun “eng” som output. Men hvis du installerer pakker til yderligere sprog som forklaret ovenfor, viser denne kommando flere sprog, som du kan bruge til at registrere tekst (som ISO 639 sprogbogskoder på 3 bogstaver).
Hvis billedet indeholder tekst på flere sprog, skal du først definere det primære sprog efterfulgt af yderligere sprog adskilt af plustegn.
$ tesseract-fangst.png output -l eng + fraHvis du vil gemme output som en søgbar PDF-fil, skal du køre en kommando i følgende format:
$ tesseract capture.png output -l eng pdfBemærk, at den søgbare PDF-fil ikke indeholder nogen redigerbar tekst. Det inkluderer det originale billede med et ekstra lag, der indeholder den genkendte tekst oven på billedet. Så mens du vil være i stand til nøjagtigt at søge på tekst i PDF-filen ved hjælp af en hvilken som helst PDF-læser, kan du ikke redigere teksten.
Et andet punkt skal du bemærke, at nøjagtigheden af tekstdetektering øges meget, hvis billedfilen er af høj kvalitet. Når du vælger, skal du altid bruge tabsfri filformater eller PNG-filer. Brug af JPG-filer giver muligvis ikke de bedste resultater.
Uddrag af tekst fra en flersidet PDF-fil
Tesseract OCR understøtter ikke indpakning af tekst fra PDF-filer. Det er dog muligt at udtrække tekst fra en flersidet PDF-fil ved at konvertere hver side til en billedfil. Kør kommandoen nedenfor for at konvertere en PDF-fil til et sæt billeder:
$ pdftoppm -png-fil.pdf-outputFor hver side i PDF-filen får du en tilsvarende “output-1.png ”,“ output-2.png ”-fil og så videre.
For at udtrække tekst fra disse billeder ved hjælp af en enkelt kommando skal du bruge en "for loop" i en bash-kommando:
$ for jeg i *.png; gør tesseract "$ i" "output- $ i" -l eng; Færdig;At køre ovenstående kommando udtrækker tekst fra alle “.png ”-filer fundet i arbejdskataloget og gem den anerkendte tekst i“ output-original_filename.txt ”filer. Du kan ændre den midterste del af kommandoen efter dine behov.
Hvis du vil kombinere alle tekstfiler, der indeholder den genkendte tekst, skal du køre kommandoen nedenfor:
$ kat *.txt> sluttede sig til.txtProcessen til udpakning af tekst fra en flersidet PDF-fil til søgbare PDF-filer er næsten den samme. Du skal levere et ekstra “pdf” -argument til kommandoen:
$ for jeg i *.png; gør tesseract "$ i" "output- $ i" -l eng pdf; Færdig;Hvis du vil kombinere alle søgbare PDF-filer, der indeholder den genkendte tekst, skal du køre kommandoen nedenfor:
$ pdfunite *.pdf sluttede sig til.pdfBåde “pdftoppm” og “pdfunite” er installeret som standard på den seneste stabile version af Ubuntu.
Fordele og ulemper ved at udtrække tekst i TXT og søgbare PDF-filer
Hvis du udtrækker genkendt tekst i TXT-filer, får du redigerbar tekstoutput. Enhver formatering af dokumenter går dog tabt (fed, kursiv karakter osv.). Søgbare PDF-filer bevarer den originale formatering, men du mister tekstredigeringsfunktioner (du kan stadig kopiere rå tekst). Hvis du åbner den søgbare PDF-fil i en hvilken som helst PDF-editor, får du indlejrede billeder i filen og ikke rå tekstoutput. Konvertering af de søgbare PDF-filer til HTML eller EPUB giver dig også indlejrede billeder.
Konklusion
Tesseract OCR er en af de mest anvendte OCR-motorer i dag. Det er en gratis open source og understøtter over hundrede sprog. Når du bruger Tesseract OCR, skal du sørge for at bruge billeder i høj opløsning og rette sprogkoder i kommandolinjeargumenter for at forbedre nøjagtigheden af tekstregistrering.


