Apache Hadoop er en big data-løsning til lagring og analyse af store datamængder. I denne artikel beskriver vi de komplekse opsætningstrin for Apache Hadoop for at komme i gang med det på Ubuntu så hurtigt som muligt. I dette indlæg installerer vi Apache Hadoop på en Ubuntu 17.10 maskine.
Ubuntu-version
Til denne vejledning bruger vi Ubuntu version 17.10 (GNU / Linux 4.13.0-38-generisk x86_64).
Opdatering af eksisterende pakker
For at starte installationen til Hadoop er det nødvendigt, at vi opdaterer vores maskine med de nyeste tilgængelige softwarepakker. Vi kan gøre dette med:
sudo apt-get opdatering && sudo apt-get -y dist-upgradeDa Hadoop er baseret på Java, skal vi installere det på vores maskine. Vi kan bruge enhver Java-version over Java 6. Her bruger vi Java 8:
sudo apt-get -y installer openjdk-8-jdk-headlessDownload af Hadoop-filer
Alle de nødvendige pakker findes nu på vores maskine. Vi er klar til at downloade de krævede Hadoop TAR-filer, så vi også kan begynde at konfigurere dem og køre et eksempelprogram med Hadoop.
I denne vejledning installerer vi Hadoop v3.0.1. Download de tilsvarende filer med denne kommando:
wget http: // spejl.cc.columbia.edu / pub / software / apache / hadoop / common / hadoop-3.0.1 / hadoop-3.0.1.tjære.gzAfhængigt af netværkshastigheden kan dette tage op til et par minutter, da filen er stor:
Downloader Hadoop
Find de nyeste Hadoop-binære filer her. Nu hvor vi har downloadet TAR-filen, kan vi udtrække i den aktuelle mappe:
tjære xvzf hadoop-3.0.1.tjære.gzDette tager nogle få sekunder at fuldføre på grund af arkivets store filstørrelse:
Hadoop blev arkiveret
Tilføjet en ny Hadoop-brugergruppe
Da Hadoop opererer over HDFS, kan et nyt filsystem også forstyrre vores eget filsystem på Ubuntu-maskinen. For at undgå denne kollision opretter vi en helt separat brugergruppe og tildeler den til Hadoop, så den indeholder sine egne tilladelser. Vi kan tilføje en ny brugergruppe med denne kommando:
addgroup hadoopVi vil se noget som:
Tilføjer Hadoop-brugergruppe
Vi er klar til at tilføje en ny bruger til denne gruppe:
useradd -G hadoop hadoopuserVær opmærksom på, at alle de kommandoer, vi kører, er som selve rodbrugeren. Med aove-kommandoen kunne vi tilføje en ny bruger til den gruppe, vi oprettede.
For at give Hadoop-brugeren mulighed for at udføre operationer er vi også nødt til at give den rootadgang. Åbn / etc / sudoers fil med denne kommando:
sudo visudoFør vi tilføjer noget, ser filen ud:
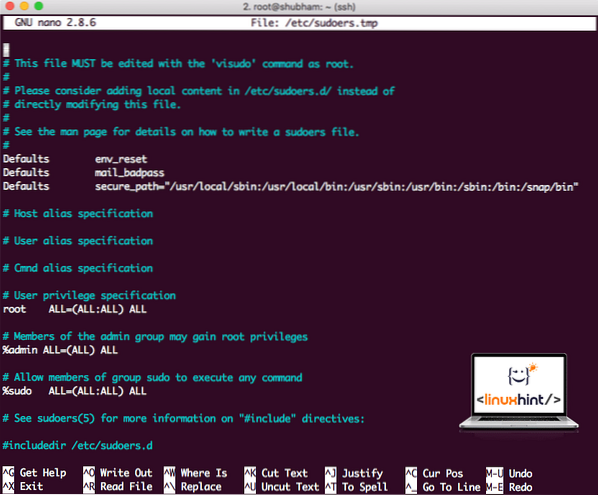
Sudoers arkiverer, før de tilføjer noget
Tilføj følgende linje i slutningen af filen:
hadoopuser ALLE = (ALLE) ALLENu ser filen ud:
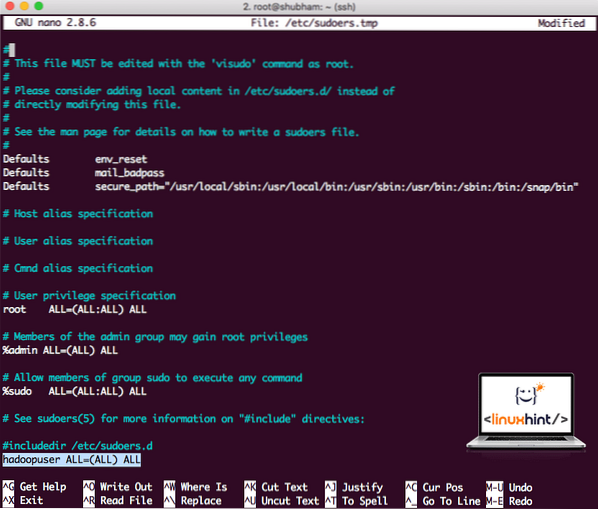
Sudoers-fil efter tilføjelse af Hadoop-bruger
Dette var hovedopsætningen for at give Hadoop en platform til at udføre handlinger. Vi er klar til at konfigurere en enkelt node Hadoop-klynge nu.
Hadoop Single Node Setup: Standalone Mode
Når det kommer til den reelle kraft fra Hadoop, er den normalt indstillet på tværs af flere servere, så den kan skaleres oven på en stor mængde datasæt, der findes i Hadoop distribueret filsystem (HDFS). Dette er normalt fint med fejlfindingsmiljøer og bruges ikke til produktionsbrug. For at holde processen enkel, vil vi forklare, hvordan vi kan udføre en enkelt nodeopsætning til Hadoop her.
Når vi er færdige med at installere Hadoop, kører vi også en prøveapplikation på Hadoop. Fra nu af kaldes Hadoop-filen som hadoop-3.0.1. lad os omdøbe det til hadoop til enklere brug:
mv hadoop-3.0.1 hadoopFilen ser nu ud som:
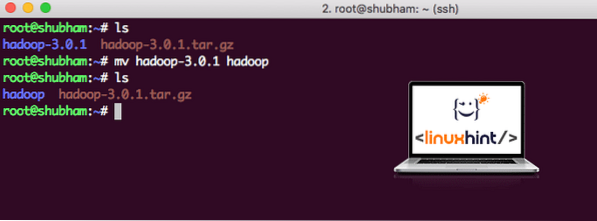
Flytter Hadoop
Tid til at gøre brug af den hadoop-bruger, vi oprettede tidligere, og tildele ejerskabet af denne fil til den bruger:
chown -R hadoopuser: hadoop / root / hadoopEn bedre placering for Hadoop vil være / usr / local / kataloget, så lad os flytte det der:
mv hadoop / usr / lokal /cd / usr / lokal /
Tilføjelse af Hadoop til stien
For at udføre Hadoop-scripts tilføjer vi det til stien nu. For at gøre dette skal du åbne bashrc-filen:
vi ~ /.bashrcTilføj disse linjer til slutningen af .bashrc-fil, så stien kan indeholde Hadoop-eksekverbare filsti:
# Konfigurer Hadoop og Java Homeeksporter HADOOP_HOME = / usr / local / hadoop
eksporter JAVA_HOME = / usr / lib / jvm / java-8-openjdk-amd64
eksporter PATH = $ PATH: $ HADOOP_HOME / bin
Filen ser ud som:
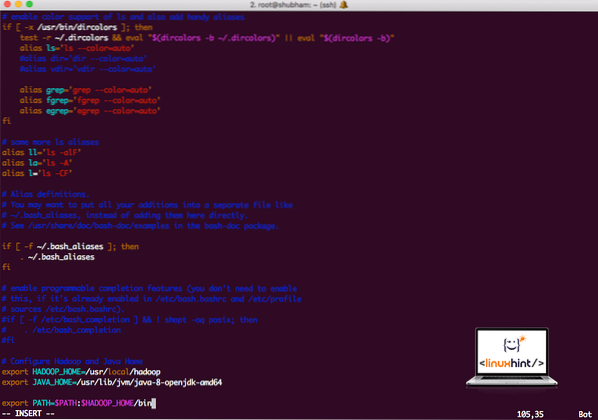
Tilføjelse af Hadoop til stien
Da Hadoop bruger Java, skal vi fortælle Hadoop-miljøfilen hadoop-env.sh hvor det er placeret. Placeringen af denne fil kan variere afhængigt af Hadoop-versioner. For let at finde, hvor denne fil er placeret, skal du køre følgende kommando lige uden for Hadoop-biblioteket:
find hadoop / -navn hadoop-env.shVi får output for filplaceringen:
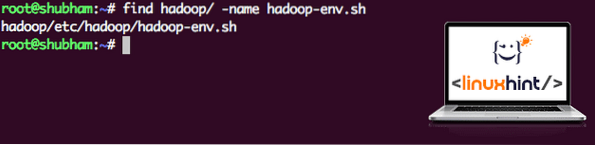
Placering af miljøfil
Lad os redigere denne fil for at informere Hadoop om Java JDK-placeringen og indsætte denne på den sidste linje i filen og gemme den:
eksporter JAVA_HOME = / usr / lib / jvm / java-8-openjdk-amd64Hadoop installation og opsætning er nu afsluttet. Vi er klar til at køre vores prøveapplikation nu. Men vent, vi har aldrig lavet en prøveansøgning!
Kører prøveapplikation med Hadoop
Faktisk kommer Hadoop-installationen med en indbygget prøveapplikation, der er klar til at køre, når vi er færdige med installation af Hadoop. Det lyder godt, ikke?
Kør følgende kommando for at køre JAR-eksemplet:
hadoop jar / rod / hadoop / del / hadoop / mapreduce / hadoop-mapreduce-eksempler-3.0.1.jar wordcount / root / hadoop / README.txt / root / outputHadoop vil vise, hvor meget behandling det gjorde ved noden:
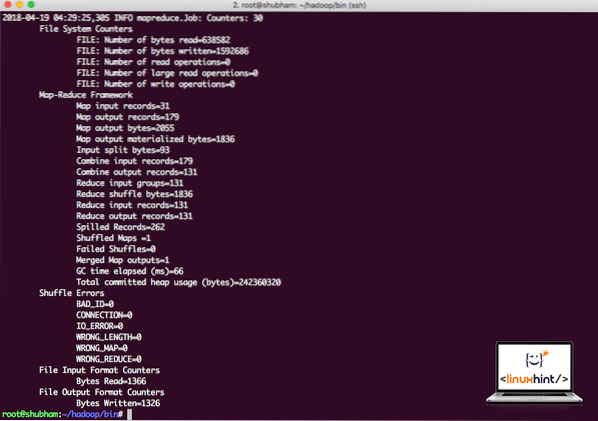
Hadoop-behandlingsstatistik
Når du udfører følgende kommando, ser vi filen del-r-00000 som en output. Gå videre og se på indholdet af output:
kat del-r-00000Du får noget som:
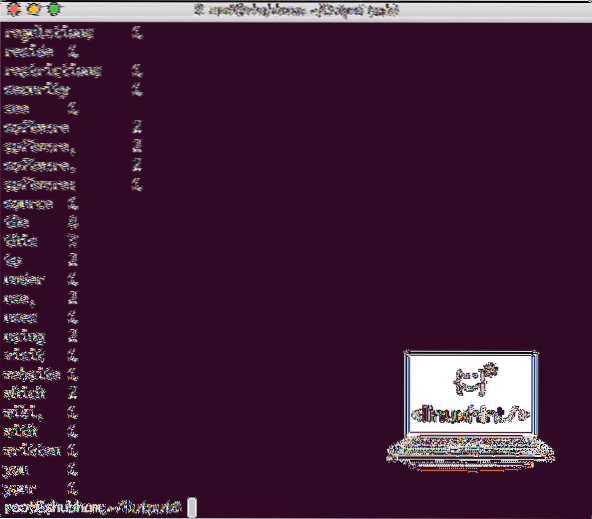
Word Count output af Hadoop
Konklusion
I denne lektion kiggede vi på, hvordan vi kan installere og begynde at bruge Apache Hadoop på Ubuntu 17.10 maskine. Hadoop er fantastisk til lagring og analyse af store mængder data, og jeg håber, at denne artikel hjælper dig med at komme hurtigt i gang med at bruge det på Ubuntu.


