- Scan filerne linje for linje.
- Opdel hver linje i felter / kolonner.
- Angiv mønstre, og sammenlign filens linjer med disse mønstre
- Udfør forskellige handlinger på de linjer, der matcher et givet mønster
I denne artikel vil vi forklare den grundlæggende brug af awk-kommandoen, og hvordan den kan bruges til at opdele en strengstreng. Vi har udført eksemplerne fra denne artikel på et Debian 10 Buster-system, men de kan let replikeres på de fleste Linux-distroer.
Den eksempelfil, vi vil bruge
Eksempelfilen for strenge, som vi vil bruge til at demonstrere brugen af awk-kommandoen, er som følger:
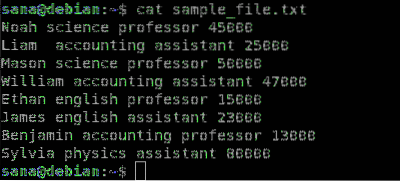
Dette er hvad hver kolonne i prøvefilen angiver:
- Den første kolonne indeholder navnet på ansatte / lærere i en skole
- Den anden kolonne indeholder det emne, som medarbejderen underviser i
- Den tredje kolonne angiver, om medarbejderen er professor eller adjunkt
- Den fjerde kolonne indeholder medarbejderens løn
Eksempel 1: Brug Awk til at udskrive alle linjer i en fil
Udskrivning af hver linje i en specificeret fil er standardadfærden for awk-kommandoen. I den følgende syntaks af awk-kommandoen specificerer vi ikke noget mønster, som awk skal udskrive, og kommandoen skal således anvende "print" -handlingen på alle linjer i filen.
Syntaks:
$ awk 'print' filnavn.txtEksempel:
I dette eksempel fortæller jeg awk-kommandoen at udskrive indholdet af min prøvefil, linje for linje.
$ awk 'print' prøvefil.txt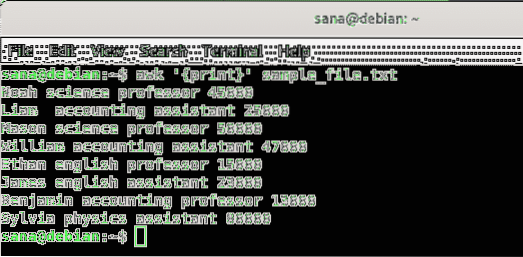
Eksempel 2: Brug awk til kun at udskrive de linjer, der matcher et givet mønster
Med awk kan du angive et mønster, og kommandoen udskriver kun de linjer, der matcher det mønster.
Syntaks:
$ awk '/ pattern_to_be_matched / print' filnavn.txtEksempel:
Fra prøvefilen, hvis jeg kun vil udskrive de (n) linje (r), der indeholder variablen 'B', kan jeg bruge følgende kommando:
$ awk '/ B / print' prøvefil.txt
For at gøre eksemplet mere meningsfuldt, lad mig kun udskrive oplysningerne om medarbejdere, der er 'professor'.
$ awk '/ professor / print' sample_file.txt
Kommandoen udskriver kun de linjer / poster, der indeholder strengen "professor", så vi har mere værdifuld information afledt af dataene.
Eksempel 3. Brug awk til at opdele filen, så kun specifikke felter / kolonner udskrives
I stedet for at udskrive hele filen kan du gøre det vanskeligt kun at udskrive specifikke kolonner i filen. Awk behandler alle ord, adskilt af hvidt mellemrum, i en linje som en kolonneoptegnelse som standard. Den gemmer posten i en $ N-variabel. Hvor $ 1 repræsenterer det første ord, gemmer $ 2 det andet ord, $ 3 det fjerde osv. $ 0 gemmer hele linjen, så hvem linjen udskrives, som forklaret i eksempel 1.
Syntaks:
$ awk 'udskriv $ N, .. .' filnavn.txtEksempel:
Den følgende kommando udskriver kun den første kolonne (navn) og den anden kolonne (emne) i min prøvefil:
$ awk 'print $ 1, $ 2' sample_file.txt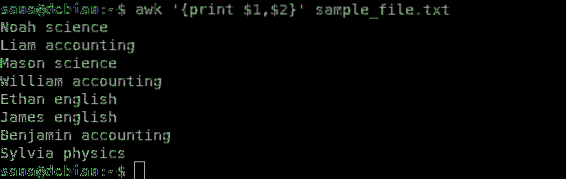
Eksempel 4: Brug Awk til at tælle og udskrive antallet af linjer, hvor et mønster matches
Du kan fortælle awk at tælle antallet af linjer, hvor et bestemt mønster matches, og derefter output det 'count'.
Syntaks:
$ awk '/ pattern_to_be_matched / ++ cnt END print "Count =", cnt'filnavn.txt
Eksempel:
I dette eksempel vil jeg tælle antallet af personer, der underviser i emnet "engelsk". Derfor vil jeg fortælle awk-kommandoen at matche mønsteret "engelsk" og udskrive antallet af linjer, hvor dette mønster matches.
$ awk '/ engelsk / ++ cnt END print "Count =", cnt' sample_file.txt
Tællingen her antyder, at 2 personer underviser i engelsk fra eksempelfiloptegnelserne.
Eksempel 5: Brug awk til kun at udskrive linjer med mere end et specifikt antal tegn
Til denne opgave bruger vi den indbyggede awk-funktion kaldet "længde". Denne funktion returnerer længden af inputstrengen. Således, hvis vi kun ønsker at udskrive linjer med mere end eller endog mindre end antallet af tegn, kan vi bruge længdefunktionen på følgende måde:
For udskrivning af linjer med tegn, der er større end et tal:
$ awk 'længde ($ 0)> n' filnavn.txtFor udskrivning af linjer med tegn mindre end et tal:
$ awk længde ($ 0) < n' filename.txtHvor n er antallet af tegn, du vil angive for en linje.
Eksempel:
Den følgende kommando udskriver kun linjerne fra min prøvefil, der har tegn på mere end 30:
$ awk 'længde ($ 0)> 30' prøvefil.txt
Eksempel 6: Brug awk til at gemme kommandooutputtet i en anden fil
Ved at bruge omdirigeringsoperatøren '>' kan du bruge kommandoen awk til at udskrive dens output til en anden fil. Det er sådan, du kan bruge det:
$ awk 'criteria_to_print "filnavn.txt> outputfil.txtEksempel:
I dette eksempel bruger jeg omdirigeringsoperatoren med min awk-kommando til kun at udskrive medarbejdernes navne (kolonne 1) til en ny fil:
$ awk 'print $ 1' sample_file.txt> medarbejdernavne.txt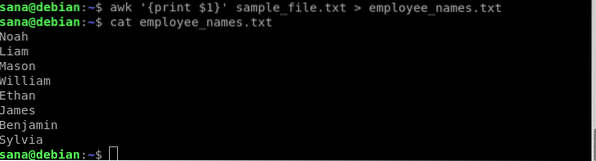
Jeg bekræftede gennem katkommandoer, at den nye fil kun indeholder navnene på de ansatte.
Eksempel 7: Brug awk til kun at udskrive ikke-tomme linjer fra en fil
Awk har nogle indbyggede kommandoer, som du kan bruge til at filtrere output. For eksempel bruges NF-kommandoen til at holde en optælling af felterne inden for den aktuelle inputpost. Her bruger vi NF-kommandoen til kun at udskrive de ikke-tomme linjer i filen:
$ awk 'NF> 0' sample_file.txtDet er klart, at du kan bruge følgende kommando til at udskrive de tomme linjer:
$ awk 'NF < 0' sample_file.txtEksempel 8: Brug awk til at tælle de samlede linjer i en fil
En anden indbygget funktion kaldet NR registrerer antallet af inputregistreringer (normalt linjer) for en given fil. Du kan bruge denne funktion i awk som følger til at tælle antallet af linjer i en fil:
$ awk 'END print NR' sample_file.txt
Dette var de grundlæggende oplysninger, du har brug for for at starte med at opdele filer med kommandoen awk. Du kan bruge kombinationen af disse eksempler til at hente mere meningsfuld information fra din strengstreng gennem awk.


