I denne artikel vil jeg vise dig, hvordan du finder og vælger elementer fra websider ved hjælp af tekst i Selen med Selenium python-biblioteket. Så lad os komme i gang.
Forudsætninger:
For at prøve kommandoer og eksempler på denne artikel skal du have:
- En Linux-distribution (helst Ubuntu) installeret på din computer.
- Python 3 installeret på din computer.
- PIP 3 installeret på din computer.
- Python virtualenv pakke installeret på din computer.
- Mozilla Firefox eller Google Chrome webbrowsere installeret på din computer.
- Skal vide, hvordan du installerer Firefox Gecko Driver eller Chrome Web Driver.
Læs min artikel for at opfylde kravene 4, 5 og 6 Introduktion til selen i Python 3.
Du kan finde mange artikler om de andre emner på LinuxHint.com. Sørg for at tjekke dem ud, hvis du har brug for hjælp.
Opsætning af et projektkatalog:
For at holde alt organiseret skal du oprette et nyt projektkatalog selen-tekst-vælg / som følger:
$ mkdir -pv selen-tekst-vælg / drivere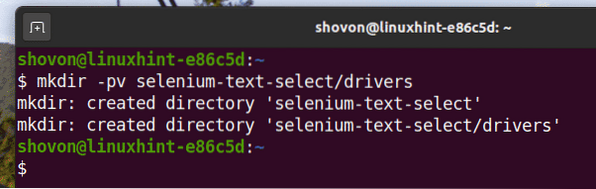
Naviger til selen-tekst-vælg / projektmappe som følger:
$ cd selen-tekst-vælg /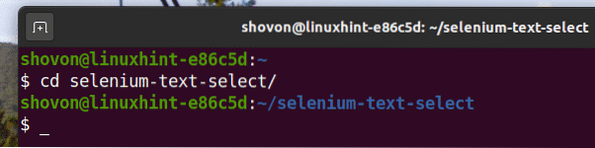
Opret et virtuelt Python-miljø i projektmappen som følger:
$ virtualenv .venv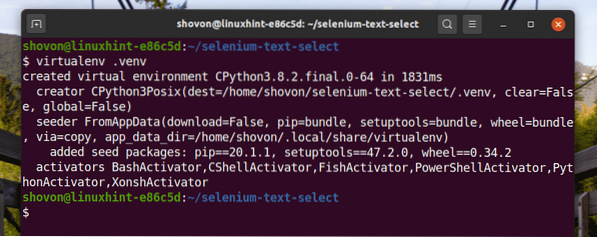
Aktivér det virtuelle miljø som følger:
$ kilde .venv / bin / aktiver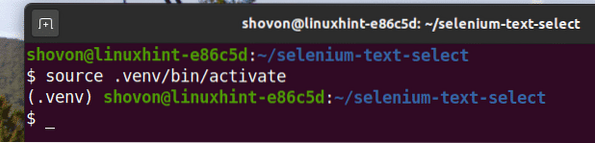
Installer Selenium Python-biblioteket ved hjælp af PIP3 som følger:
$ pip3 installer selen
Download og installer alle de krævede webdrivere i drivere / projektmappe. Jeg har forklaret processen med at downloade og installere webdrivere i min artikel Introduktion til selen i Python 3.
Finde elementer efter tekst:
I dette afsnit vil jeg vise dig nogle eksempler på at finde og vælge websideelementer ved hjælp af tekst med Selenium Python-biblioteket.
Jeg begynder med det enkleste eksempel på valg af websideelementer efter tekst, valg af links fra websiden.
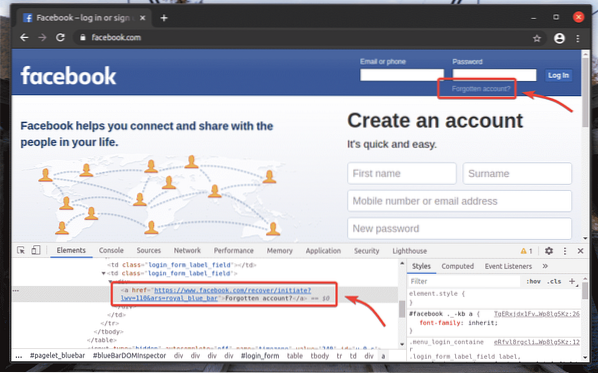
På login-siden på facebook.com, vi har et link Glemt konto? Som du kan se på skærmbilledet nedenfor. Lad os vælge dette link med Selen.
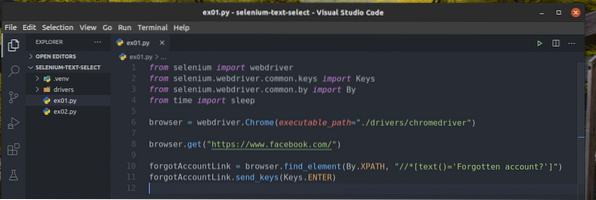
Opret et nyt Python-script ex01.py og indtast følgende linjer med koder i den.
fra selen import webdriverfra selen.webdriver.almindelige.nøgler importerer nøgler
fra selen.webdriver.almindelige.ved import af
fra tidspunktet import søvn
browser = webdriver.Chrome (eksekverbar_sti = "./ drivere / chromedriver ")
browser.get ("https: // www.Facebook.com / ")
forgotAccountLink = browser.find_element (af.XPATH, "
// * [text () = 'Glemt konto?'] ")
glemteAccountLink.send_keys (nøgler.GÅ IND)
Når du er færdig, skal du gemme ex01.py Python-script.
Linje 1-4 importerer alle de nødvendige komponenter til Python-programmet.

Linje 6 opretter en Chrome browser objekt ved hjælp af chromedriver binær fra drivere / projektmappe.

Linje 8 beder browseren om at indlæse hjemmesiden facebook.com.

Linje 10 finder det link, der har teksten Glemt konto? Brug af XPath-vælger. Til det har jeg brugt XPath-vælgeren // * [text () = 'Glemt konto?'].
XPath-vælgeren starter med //, hvilket betyder, at elementet kan være hvor som helst på siden. Det * symbol fortæller Selen at vælge et hvilket som helst mærke (-en eller s eller spændvidde, etc.), der matcher betingelsen inden for de firkantede parenteser []. Her er betingelsen, at elementets tekst er lig med Glemt konto?

Det tekst() XPath-funktionen bruges til at hente teksten til et element.
For eksempel, tekst() vender tilbage Hej Verden hvis det vælger følgende HTML-element.
Hej VerdenLinie 11 sender

Kør Python-scriptet ex01.py med følgende kommando:
$ python ex01.py
Som du kan se, finder, vælger og trykker webbrowseren på
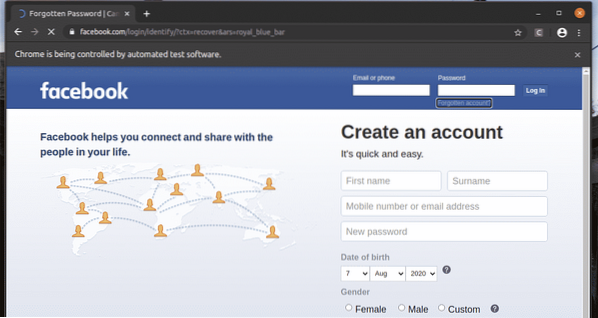
Det Glemt konto? Linket fører browseren til den næste side.
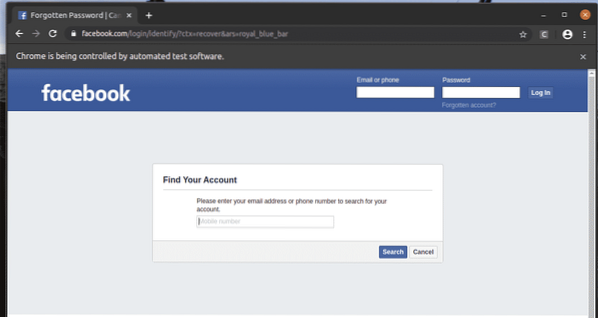
På samme måde kan du nemt søge efter elementer, der har den ønskede attributværdi.
Her, den Log på knappen er en input element, der har værdi attribut Log på. Lad os se, hvordan du vælger dette element ved hjælp af tekst.
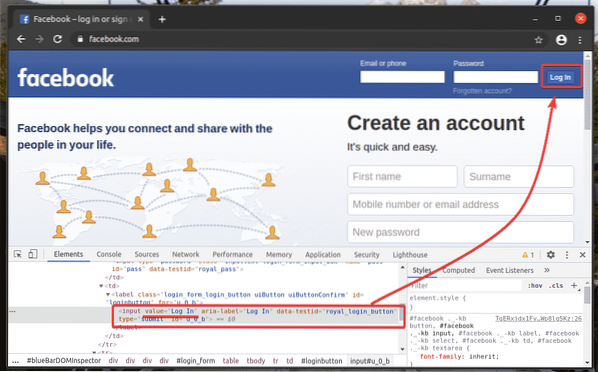
Opret et nyt Python-script ex02.py og indtast følgende linjer med koder i den.
fra selen import webdriverfra selen.webdriver.almindelige.nøgler importerer nøgler
fra selen.webdriver.almindelige.ved import af
fra tidspunktet import søvn
browser = webdriver.Chrome (eksekverbar_sti = "./ drivere / chromedriver ")
browser.get ("https: // www.Facebook.com / ")
sove (5)
emailInput = browser.find_element (af.XPATH, "// input [@ id = 'email']")
passwordInput = browser.find_element (af.XPATH, "// input [@ id = 'pass']")
loginButton = browser.find_element (af.XPATH, "// * [@ value = 'Log In']")
emailInput.send_keys ('[email protected]')
sove (5)
passwordInput.send_keys ('hemmelig pas')
sove (5)
loginKnap.send_keys (nøgler.GÅ IND)
Når du er færdig, skal du gemme ex02.py Python-script.
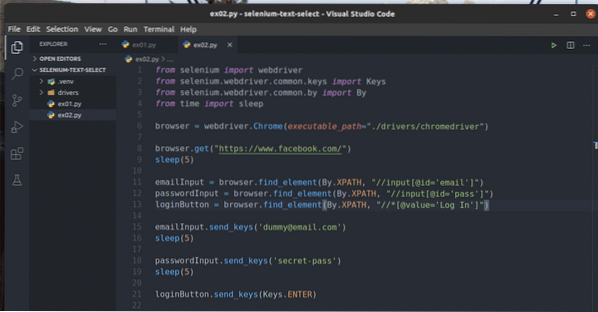
Linje 1-4 importerer alle de nødvendige komponenter.

Linje 6 opretter en Chrome browser objekt ved hjælp af chromedriver binær fra drivere / projektmappe.

Linje 8 beder browseren om at indlæse hjemmesiden facebook.com.
Alt sker så hurtigt, når du kører scriptet. Så jeg har brugt søvn() fungerer mange gange i ex02.py til forsinkelse af browserkommandoer. På denne måde kan du observere, hvordan alt fungerer.

Linje 11 finder tekstfeltet til e-mail-input og gemmer en reference for elementet i emailInput variabel.

Linie 12 finder tekstfeltet til e-mail-input og gemmer en reference for elementet i emailInput variabel.

Linie 13 finder det inputelement, der har attributten værdi af Log på ved hjælp af XPath-vælger. Til det har jeg brugt XPath-vælgeren // * [@ value = 'Log In'].
XPath-vælgeren starter med //. Det betyder, at elementet kan være hvor som helst på siden. Det * symbol fortæller Selen at vælge et hvilket som helst mærke (input eller s eller spændvidde, etc.), der matcher betingelsen inden for de firkantede parenteser []. Her er betingelsen elementattributten værdi er lig med Log på.

Linje 15 sender input [e-mailbeskyttet] til tekstfeltet til e-mail-input, og linje 16 forsinker den næste handling.

Linie 18 sender input-hemmelighedskortet til tekstfeltet til indtastning af adgangskode, og linje 19 forsinker den næste operation.

Linie 21 sender

Kør ex02.py Python-script med følgende kommando:
$ python3 ex02.py
Som du kan se, er tekstfelterne med e-mail og adgangskode fyldt med vores dummy-værdier og Log på der trykkes på knappen.
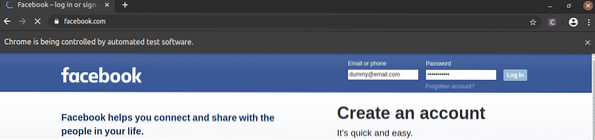
Derefter navigerer siden til den næste side.
Finde elementer efter delvis tekst:
I det tidligere afsnit har jeg vist dig, hvordan du finder elementer efter specifik tekst. I dette afsnit vil jeg vise dig, hvordan du finder elementer fra websider ved hjælp af delvis tekst.
I eksemplet, ex01.py, Jeg har søgt efter det linkelement, der har teksten Glemt konto?. Du kan søge i det samme linkelement ved hjælp af delvis tekst som f.eks Glemt acc. For at gøre det kan du bruge indeholder() XPath-funktion, som vist i linje 10 i ex03.py. Resten af koderne er de samme som i ex01.py. Resultaterne vil være de samme.
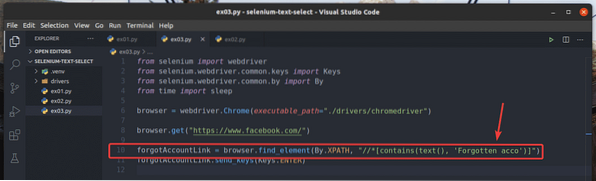
I linje 10 i ex03.py, udvælgelsesbetingelsen anvendt indeholder (kilde, tekst) XPath-funktion. Denne funktion tager to argumenter, kilde, og tekst.
Det indeholder() funktion kontrollerer, om tekst givet i det andet argument matcher delvist kilde værdi i det første argument.
Kilden kan være teksten til elementet (tekst()) eller elementets attributværdi (@attr_name).
I ex03.py, elementets tekst er markeret.

En anden nyttig XPath-funktion til at finde elementer fra websiden ved hjælp af delvis tekst er starter med (kilde, tekst). Denne funktion har de samme argumenter som indeholder() funktion og bruges på samme måde. Den eneste forskel er, at starter med () funktion kontrollerer, om det andet argument tekst er startstrengen for det første argument kilde.
Jeg har omskrevet eksemplet ex03.py for at søge efter det element, som teksten starter med Glemt, som du kan se i linje 10 i ex04.py. Resultatet er det samme som i ex02 og ex03.py.
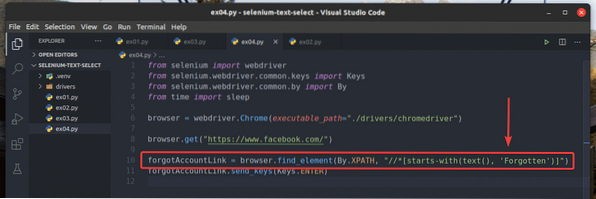
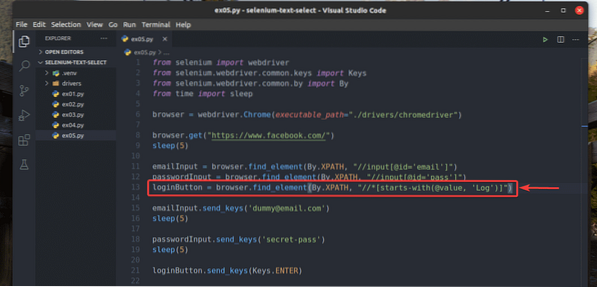
Jeg har også skrevet om ex02.py så den søger efter det inputelement, som værdi attribut starter med Log, som du kan se i linje 13 i ex05.py. Resultatet er det samme som i ex02.py.
Konklusion:
I denne artikel har jeg vist dig, hvordan du finder og vælger elementer fra websider efter tekst med Selenium Python-biblioteket. Nu skal du være i stand til at finde elementer fra websider efter specifik tekst eller delvis tekst med Selenium Python-biblioteket.


