Inden du bruger pandas pivottabel, skal du sørge for at forstå dine data og spørgsmål, du prøver at løse gennem pivottabellen. Ved at bruge denne metode kan du producere effektive resultater. Vi vil uddybe i denne artikel, hvordan man opretter en pivottabel i pandas python.
Læs data fra Excel-fil
Vi har downloadet en excel-database over fødevaresalg. Før du starter implementeringen, skal du installere nogle nødvendige pakker til læsning og skrivning af Excel-databasefiler. Skriv følgende kommando i terminalsektionen i din pycharm-editor:
pip installer xlwt openpyxl xlsxwriter xlrd
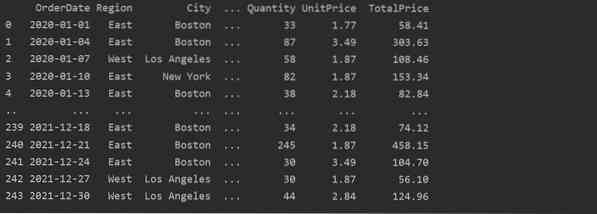
Læs nu data fra Excel-arket. Importer de påkrævede pandas biblioteker, og skift stien til din database. Derefter kan data hentes fra filen ved at køre følgende kode.
importer pandaer som pdimporter numpy som np
dtfrm = pd.read_excel ('C: / Brugere / DELL / Desktop / foodsalesdata.xlsx ')
udskrive (dtfrm)
Her læses dataene fra excel-databasen over fødevaresalg og overføres til dataframe-variablen.
Opret pivottabel ved hjælp af Pandas Python
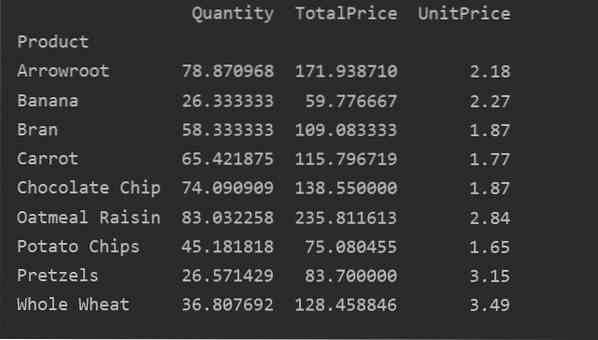
Nedenfor har vi oprettet en simpel drejetabel ved hjælp af fødevaresalgsdatabasen. To parametre kræves for at oprette en pivottabel. Den første er data, som vi har overført til datarammen, og den anden er et indeks.
Pivotdata på et indeks
Indekset er funktionen i en pivottabel, der giver dig mulighed for at gruppere dine data baseret på krav. Her har vi taget 'Produkt' som indeks for at oprette en grundlæggende pivottabel.
importer pandaer som pdimporter numpy som np
dataframe = pd.read_excel ('C: / Brugere / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivottabel (dataframe, index = ["Produkt"])
udskriv (pivot_tble)
Følgende resultat vises efter kørsel af ovenstående kildekode:
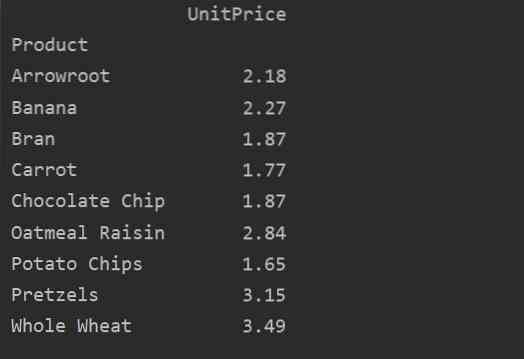
Definér kolonner eksplicit
For mere analyse af dine data skal du eksplicit definere kolonnenavnene med indekset. For eksempel vil vi vise den eneste UnitPrice for hvert produkt i resultatet. Til dette formål skal du tilføje parameteren værdier i din pivottabel. Den følgende kode giver dig det samme resultat:
importer pandaer som pdimporter numpy som np
dataframe = pd.read_excel ('C: / Brugere / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivottabel (dataframe, index = 'Product', values = 'UnitPrice')
udskriv (pivot_tble)
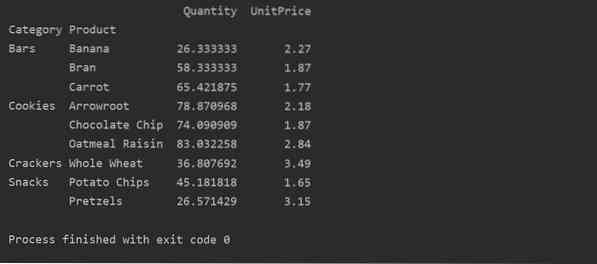
Pivotdata med multiindeks
Data kan grupperes baseret på mere end en funktion som et indeks. Ved at bruge multiindeksmetoden kan du få mere specifikke resultater til dataanalyse. For eksempel hører produkter under forskellige kategorier. Så du kan vise indekset 'Produkt' og 'Kategori' med tilgængeligt 'Antal' og 'Enhedspris' for hvert produkt som følger:
importer pandaer som pdimporter numpy som np
dataframe = pd.read_excel ('C: / Brugere / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (dataframe, index = ["Category", "Product"], values = ["UnitPrice", "Quantity"])
udskriv (pivot_tble)
Anvendelse af aggregeringsfunktion i pivottabellen
I en pivottabel kan aggfunc anvendes til forskellige funktionsværdier. Den resulterende tabel er opsummeringen af funktionsdata. Den samlede funktion gælder for dine gruppedata i pivottabel. Som standard er den samlede funktion np.betyde(). Men baseret på brugerkrav kan forskellige samlede funktioner gælde for forskellige datafunktioner.
Eksempel:
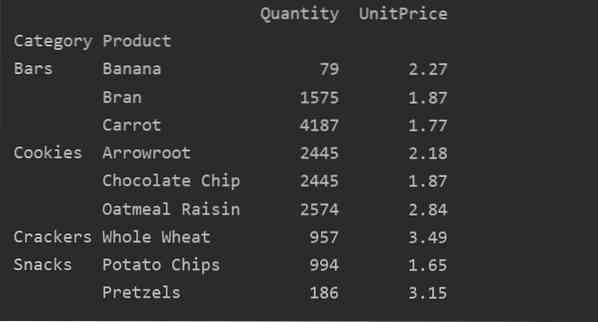
Vi har anvendt samlede funktioner i dette eksempel. Np.funktionen sum () bruges til funktionen 'Mængde' og np.middel () funktion for 'UnitPrice' funktion.
importer pandaer som pdimporter numpy som np
dataframe = pd.read_excel ('C: / Brugere / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivottabel (dataframe, index = ["Category", "Product"], aggfunc = 'Quantity': np.sum, 'UnitPrice': np.betyde)
udskriv (pivot_tble)
Efter anvendelse af aggregeringsfunktionen til forskellige funktioner får du følgende output:
Ved hjælp af værdiparameteren kan du også anvende en samlet funktion til en bestemt funktion. Hvis du ikke angiver funktionens værdi, samler den din databases numeriske funktioner. Ved at følge den givne kildekode kan du anvende den samlede funktion til en bestemt funktion:
importer pandaer som pdimporter numpy som np
dataframe = pd.read_excel ('C: / Brugere / DELL / Desktop / foodsalesdata.xlsx ')
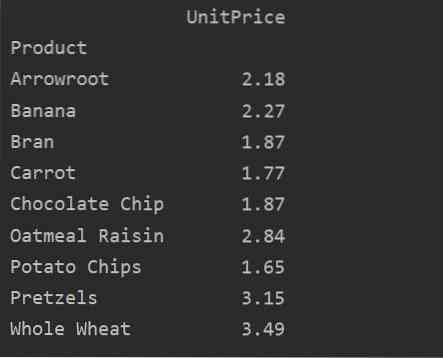
pivot_tble = pd.pivottabel (dataframe, index = ['Product'], values = ['UnitPrice'], aggfunc = np.betyde)
udskriv (pivot_tble)
Forskelligt mellem værdier vs. Kolonner i pivottabel
Værdierne og kolonnerne er det vigtigste forvirrende punkt i pivottabellen. Det er vigtigt at bemærke, at kolonner er valgfri felter, der viser den resulterende tabels værdier vandret øverst. Aggregationsfunktionen aggfunc gælder for det værdifelt, som du angiver.
importer pandaer som pdimporter numpy som np
dataframe = pd.read_excel ('C: / Brugere / DELL / Desktop / foodsalesdata.xlsx ')
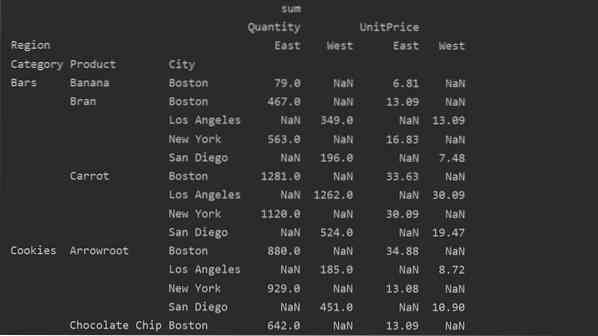
pivot_tble = pd.pivottabel (dataframe, index = ['Category', 'Product', 'City'], values = ['UnitPrice', 'Quantity'],
kolonner = ['Region'], aggfunc = [np.sum])
udskriv (pivot_tble)
Håndtering af manglende data i pivottabellen
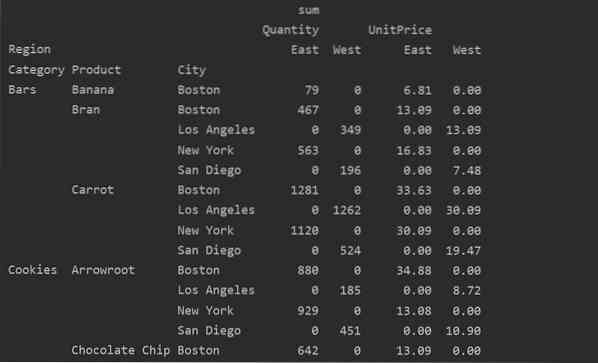
Du kan også håndtere de manglende værdier i pivottabellen ved hjælp af 'fill_value' Parameter. Dette giver dig mulighed for at erstatte NaN-værdierne med en ny værdi, som du giver til at udfylde.
For eksempel fjernede vi alle nulværdier fra ovenstående resultattabel ved at køre følgende kode og erstatter NaN-værdierne med 0 i hele den resulterende tabel.
importer pandaer som pdimporter numpy som np
dataframe = pd.read_excel ('C: / Brugere / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivottabel (dataframe, index = ['Category', 'Product', 'City'], values = ['UnitPrice', 'Quantity'],
kolonner = ['Region'], aggfunc = [np.sum], fill_value = 0)
udskriv (pivot_tble)
Filtrering i drejetabel
Når resultatet er genereret, kan du anvende filteret ved hjælp af standard dataframe-funktionen. Lad os tage et eksempel. Filtrer de produkter, hvis UnitPrice er mindre end 60. Det viser de produkter, hvis pris er mindre end 60.
importer pandaer som pdimporter numpy som np
dataframe = pd.read_excel ('C: / Brugere / DELL / Desktop / foodsalesdata.xlsx ', index_col = 0)
pivot_tble = pd.pivottabel (dataframe, index = 'Product', values = 'UnitPrice', aggfunc = 'sum')
low_price = pivot_tble [pivot_tble ['UnitPrice'] < 60]
udskriv (lavpris)

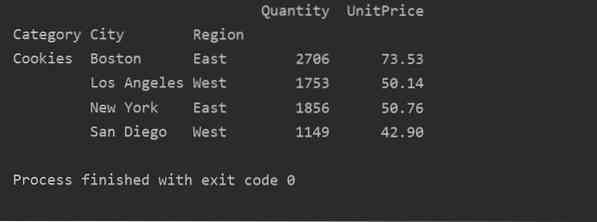
Ved at bruge en anden forespørgselsmetode kan du filtrere resultater. For eksempel har vi for eksempel filtreret cookies-kategorien baseret på følgende funktioner:
importer pandaer som pdimporter numpy som np
dataframe = pd.read_excel ('C: / Brugere / DELL / Desktop / foodsalesdata.xlsx ', index_col = 0)
pivot_tble = pd.pivottabel (dataframe, index = ["Category", "City", "Region"], values = ["UnitPrice", "Quantity"], aggfunc = np.sum)
pt = pivot_tble.forespørgsel ('Category == ["Cookies"]')
print (pt)
Produktion:
Visualiser pivottabeldataene
Følg følgende metode for at visualisere pivottabeldataene:
importer pandaer som pdimporter numpy som np
importer matplotlib.pyplot som plt
dataframe = pd.read_excel ('C: / Brugere / DELL / Desktop / foodsalesdata.xlsx ', index_col = 0)
pivot_tble = pd.pivottabel (dataframe, index = ["Category", "Product"], values = ["UnitPrice"])
pivot_tble.plot (kind = 'bar');
plt.at vise()
I ovenstående visualisering har vi vist enhedsprisen for de forskellige produkter sammen med kategorier.

Konklusion
Vi undersøgte, hvordan du kan generere en pivottabel fra datarammen ved hjælp af Pandas python. En pivottabel giver dig mulighed for at generere dyb indsigt i dine datasæt. Vi har set, hvordan man genererer en simpel pivottabel ved hjælp af multiindeks og anvender filtrene på pivottabeller. Desuden har vi også vist at plotte pivottabeldata og udfylde manglende data.


