Antag at du er ejer af en stor forsyningsbutik i det amt, hvor du bor. Antag, at du bor i et stort område, som ikke er et kommercielt område. Du er ikke den eneste med en forsyningsbutik i området; du har et par konkurrenter. Og så kommer det dig op, at du skal registrere dine kunders telefonnumre i en træningsbog. Selvfølgelig er træningsbogen lille, og du kan ikke registrere alle telefonnumre til alle dine kunder.
Så du beslutter dig for kun at registrere dine faste kunders telefonnumre. Og så har du en tabel med to kolonner. Kolonnen til venstre har kundernes navne, og kolonnen til højre har de tilsvarende telefonnumre. På denne måde er der en kortlægning mellem kundenavne og telefonnumre. Den højre kolonne i tabellen kan betragtes som kernen hash tabel. Kundenavne kaldes nu nøgler, og telefonnumrene kaldes værdier. Bemærk, at når en kunde går på overførsel, bliver du nødt til at annullere sin række, så rækken er tom eller erstattes med en ny fast kundes. Bemærk også, at med tiden kan antallet af faste kunder stige eller falde, og så kan bordet vokse eller krympe.
Antag, at der er en klub med landmænd i et amt som et andet eksempel på kortlægning. Selvfølgelig vil ikke alle landmænd være medlemmer af klubben. Nogle medlemmer af klubben vil ikke være faste medlemmer (til stede og bidrag). Bar-manden kan beslutte at registrere navnene på medlemmerne og deres valg af drikke. Han udvikler en tabel med to kolonner. I venstre kolonne skriver han navnene på klubmedlemmerne. I højre kolonne skriver han det tilsvarende valg af drikke.
Der er et problem her: der er dubletter i højre kolonne. Det vil sige, det samme navn på en drink findes mere end én gang. Med andre ord, forskellige medlemmer drikker den samme søde drink eller den samme alkoholholdige drik, mens andre medlemmer drikker en anden sød eller alkoholisk drink. Stangmanden beslutter at løse dette problem ved at indsætte en smal søjle mellem de to søjler. I denne midterste kolonne, der begynder fra toppen, nummererer han rækkerne, der begynder med nul (i.e. 0, 1, 2, 3, 4 osv.), går ned, et indeks pr. række. Med dette løses hans problem, da et medlemsnavn nu kortlægges til et indeks og ikke til navnet på en drink. Så da en drink identificeres med et indeks, kortlægges et kundenavn til det tilsvarende indeks.
Værdikolonnen (drinks) alene danner den grundlæggende hash-tabel. I den modificerede tabel danner kolonnen med indekser og deres tilknyttede værdier (med eller uden dubletter) en normal hash-tabel - den fulde definition af en hash-tabel er angivet nedenfor. Tasterne (første kolonne) udgør ikke nødvendigvis en del af hash-tabellen.
Som et andet eksempel igen, overvej en netværksserver, hvor en bruger fra hans klientcomputer kan tilføje nogle oplysninger, slette nogle oplysninger eller ændre nogle oplysninger. Der er mange brugere til serveren. Hvert brugernavn svarer til en adgangskode, der er gemt på serveren. De, der vedligeholder serveren, kan se brugernavne og tilhørende adgangskode og således være i stand til at ødelægge brugernes arbejde.
Så ejeren af serveren beslutter at producere en funktion, der krypterer en adgangskode, før den gemmes. En bruger logger ind på serveren med sin normale forståede adgangskode. Men nu er hver adgangskode gemt i en krypteret form. Hvis nogen ser en krypteret adgangskode og forsøger at logge ind ved hjælp af den, fungerer den ikke, fordi login, modtager en forstået adgangskode af serveren og ikke en krypteret adgangskode.
I dette tilfælde er den forståede adgangskode nøglen, og den krypterede adgangskode er værdien. Hvis den krypterede adgangskode er i en kolonne med krypterede adgangskoder, er denne kolonne en grundlæggende hash-tabel. Forud for denne kolonne er der en anden kolonne med indekser, der begynder med nul, så hver krypterede adgangskode er knyttet til et indeks, så danner både kolonnen med indekser og den krypterede adgangskodekolonne en normal hash-tabel. Tasterne er ikke nødvendigvis en del af hash-tabellen.
Bemærk i dette tilfælde, at hver tast, som er en forstået adgangskode, svarer til et brugernavn. Så der er et brugernavn, der svarer til en nøgle, der er tilknyttet et indeks, som er knyttet til en værdi, der er en krypteret nøgle.
Definitionen af en hash-funktion, den fulde definition af en hash-tabel, betydningen af en matrix og andre detaljer er angivet nedenfor. Du skal have viden om markører (referencer) og sammenkædede lister for at sætte pris på resten af denne tutorial.
Betydning af Hash-funktion og Hash-tabel
Array
Et array er et sæt på hinanden følgende hukommelsesplaceringer. Alle placeringer er af samme størrelse. Værdien på den første placering tilgås med indekset, 0; værdien på den anden placering tilgås med indekset 1; den tredje værdi tilgås med indekset, 2; fjerde med indeks, 3; og så videre. En matrix kan normalt ikke øges eller formindskes. For at ændre størrelsen (længden) af en matrix skal der oprettes et nyt array, og tilsvarende værdier kopieres til det nye array. Værdierne for en matrix er altid af samme type.
Hash-funktion
I software er en hash-funktion en funktion, der tager en nøgle og producerer et tilsvarende indeks for en matrixcelle. Arrayet har en fast størrelse (fast længde). Antallet af nøgler har vilkårlig størrelse, normalt større end størrelsen på arrayet. Indekset, der er resultatet af hash-funktionen, kaldes en hash-værdi eller en digest eller en hash-kode eller simpelthen en hash.
Hash-bord
En hash-tabel er en matrix med værdier, til hvis indekser nøgler er kortlagt. Tasterne kortlægges indirekte til værdierne. Faktisk siges det, at tasterne kortlægges til værdierne, da hvert indeks er knyttet til en værdi (med eller uden dubletter). Den funktion, der laver kortlægning (i.e. hashing) relaterer nøgler til matrixindekserne og ikke rigtig til værdierne, da der muligvis er duplikater i værdierne. Følgende diagram illustrerer en hash-tabel for navnene på personer og deres telefonnumre. Matrixcellerne (slots) kaldes spande.
Bemærk, at nogle skovle er tomme. En hash-tabel må ikke nødvendigvis have værdier i alle dens spande. Værdierne i skovlene skal ikke nødvendigvis være i stigende rækkefølge. Imidlertid er indekserne, som de er knyttet til, i stigende rækkefølge. Pilene angiver kortlægningen. Bemærk, at tasterne ikke er i en matrix. De behøver ikke at være i nogen struktur. En hash-funktion tager en hvilken som helst nøgle og skyder et indeks ud for en matrix. Hvis der ikke er nogen værdi i skovlen, der er knyttet til indekshashet, kan der sættes en ny værdi i skovlen. Det logiske forhold er mellem nøglen og indekset og ikke mellem nøglen og den værdi, der er knyttet til indekset.
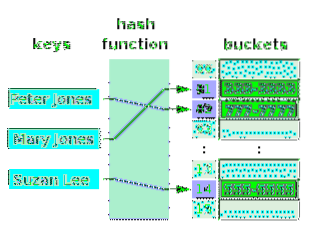
Værdierne for en matrix, som dem i denne hash-tabel, er altid af samme datatype. En hash-tabel (spande) kan forbinde nøgler til værdierne for forskellige datatyper. I dette tilfælde er matrixens værdier alle markører, der peger på forskellige værdityper.
En hash-tabel er en matrix med en hash-funktion. Funktionen tager en nøgle og hasher et tilsvarende indeks og forbinder så nøgler til værdier i arrayet. Tasterne behøver ikke at være en del af hash-tabellen.
Hvorfor Array og ikke sammenkædet liste til Hash-tabel
Arrayet for en hash-tabel kan erstattes af en sammenkædet liste datastruktur, men der ville være et problem. Det første element i en sammenkædet liste er naturligvis ved indeks, 0; det andet element er naturligvis ved indeks, 1; den tredje er naturligvis ved indeks, 2; og så videre. Problemet med den linkede liste er, at for at hente en værdi, skal listen gentages, og det tager tid. Adgang til en værdi i en matrix sker ved tilfældig adgang. Når indekset er kendt, opnås værdien uden iteration; denne adgang er hurtigere.
Kollision
Hash-funktionen tager en nøgle og hashes det tilsvarende indeks, for at læse den tilknyttede værdi eller for at indsætte en ny værdi. Hvis formålet er at læse en værdi, er der hidtil ikke noget problem (intet problem). Men hvis formålet er at indsætte en værdi, kan det hashede indeks muligvis allerede have en tilknyttet værdi, og det er en kollision; den nye værdi kan ikke placeres, hvor der allerede er en værdi. Der er måder at løse kollision på - se nedenfor.
Hvorfor kollision forekommer
I eksemplet med levering af butikker ovenfor er kundenavnene nøglerne, og navnene på drikkevarer er værdierne. Bemærk, at kunderne er for mange, mens arrayet har en begrænset størrelse og ikke kan tage alle kunderne. Så kun drikkevarer fra faste kunder er gemt i arrayet. Kollisionen ville forekomme, når en ikke-regelmæssig kunde bliver regelmæssig. Kunder til butikken danner et stort sæt, mens antallet af skovle til kunder i arrayet er begrænset.
Med hash-tabeller er det værdierne for tasterne, der er meget sandsynlige, der registreres. Når en nøgle, der ikke var sandsynlig, bliver sandsynlig, ville der sandsynligvis være en kollision. Faktisk forekommer kollision altid med hash-tabeller.
Grundlæggende kollisionsopløsning
To tilgange til kollisionsopløsning kaldes separat lænkning og åben adressering. I teorien bør nøglerne ikke være i datastrukturen eller ikke være en del af hash-tabellen. Begge tilgange kræver imidlertid, at nøglekolonnen går foran hash-tabellen og bliver en del af den overordnede struktur. I stedet for at nøgler er i nøglekolonnen, kan markører til tasterne være i nøglekolonnen.
En praktisk hash-tabel indeholder en nøglekolonne, men denne nøglekolonne er ikke officielt en del af hash-tabellen.
Enten tilgang til opløsning kan have tomme spande, ikke nødvendigvis i slutningen af arrayet.
Separat lænkning
Når der sker en separat sammenkædning, tilføjes den nye værdi til højre (ikke over eller under) for den kolliderede værdi, når der opstår en kollision. Så to eller tre værdier ender med at have det samme indeks. Sjældent skal mere end tre have det samme indeks.
Kan mere end en værdi virkelig have det samme indeks i en matrix? - Ingen. Så i mange tilfælde er den første værdi for indekset en markør til en sammenkædet liste datastruktur, der indeholder en, to eller tre kolliderede værdier. Følgende diagram er et eksempel på en hash-tabel til separat sammenkædning af kunder og deres telefonnumre:
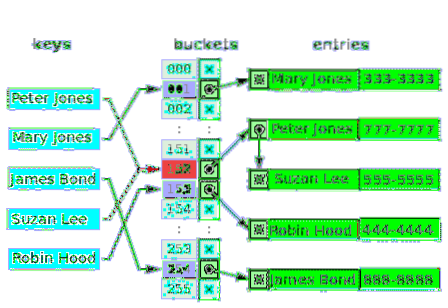
De tomme skovle er markeret med bogstavet x. Resten af slots har henvisninger til sammenkædede lister. Hvert element på den sammenkædede liste har to datafelter: et for kundenavnet og det andet for telefonnummeret. Konflikt opstår for nøglerne: Peter Jones og Suzan Lee. De tilsvarende værdier består af to elementer på en sammenkædet liste.
For modstridende nøgler er kriteriet for at indsætte værdi det samme kriterium, der bruges til at lokalisere (og læse) værdien.
Åbn adressering
Med åben adressering gemmes alle værdier i bucket-arrayet. Når der opstår konflikt, indsættes den nye værdi i en tom spand, den nye værdi for konflikten efter et eller flere kriterier. Kriteriet, der bruges til at indsætte en værdi i konflikt, er det samme kriterium, der bruges til at lokalisere (søge og læse) værdien.
Følgende diagram illustrerer konfliktløsning med åben adressering:
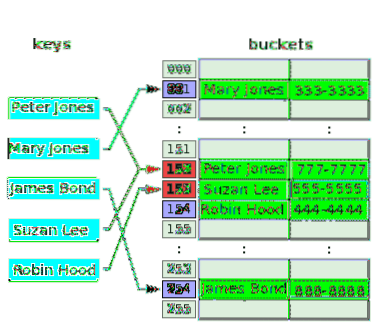 Hash-funktionen tager nøglen, Peter Jones, og hasher indekset, 152, og gemmer sit telefonnummer ved den tilknyttede spand. Efter et stykke tid hash-funktionen hash det samme indeks, 152 fra nøglen, Suzan Lee, kolliderer med indekset for Peter Jones. For at løse dette lagres værdien for Suzan Lee i spanden i det næste indeks, 153, som var tom. Hash-funktionen hashes indekset, 153 for nøglen, Robin Hood, men dette index er allerede blevet brugt til at løse konflikten for en tidligere nøgle. Så værdien for Robin Hood placeres i den næste tomme spand, det vil sige indeks 154.
Hash-funktionen tager nøglen, Peter Jones, og hasher indekset, 152, og gemmer sit telefonnummer ved den tilknyttede spand. Efter et stykke tid hash-funktionen hash det samme indeks, 152 fra nøglen, Suzan Lee, kolliderer med indekset for Peter Jones. For at løse dette lagres værdien for Suzan Lee i spanden i det næste indeks, 153, som var tom. Hash-funktionen hashes indekset, 153 for nøglen, Robin Hood, men dette index er allerede blevet brugt til at løse konflikten for en tidligere nøgle. Så værdien for Robin Hood placeres i den næste tomme spand, det vil sige indeks 154.
Metoder til løsning af konflikter for separat lænkning og åben adressering
Separat kæde har sine metoder til løsning af konflikter, og åben adressering har også sine egne metoder til løsning af konflikter.
Metoder til løsning af separate lænkningskonflikter
Metoderne til separate kædeformede hash-tabeller forklares kort nu:
Separat lænkning med sammenkædede lister
Denne metode er som forklaret ovenfor. Hvert element på den sammenkædede liste skal dog ikke nødvendigvis have nøglefeltet (e.g. kundenavnfelt ovenfor).
Separat kæde med listehovedceller
I denne metode lagres det første element på den linkede liste i en bucket i arrayet. Dette er muligt, hvis datatypen for arrayet er elementet i den linkede liste.
Separat kæde med andre strukturer
Enhver anden datastruktur, såsom det selvbalancerende binære søgetræ, der understøtter de krævede operationer, kan bruges i stedet for den linkede liste - se senere.
Metoder til løsning af åbne adresseringskonflikter
En metode til løsning af konflikt i åben adressering kaldes probesekvens. Tre kendte probesekvenser forklares kort nu:
Lineær sondering
Ved lineær sondering, når der opstår en konflikt, ledes efter den nærmeste tomme spand under spanden ved konflikt. Også med lineær sondering gemmes både nøglen og dens værdi i den samme spand.
Kvadratisk sondering
Antag, at konflikt opstår ved indeks H. Den næste tomme plads (spand) ved indeks H + 12 anvendes; hvis det allerede er optaget, så er det næste tomme ved H + 22 bruges, hvis den allerede er optaget, så den næste tomme ved H + 32 bruges osv. Der er varianter til dette.
Dobbelt hash
Med dobbelt hashing er der to hash-funktioner. Den første beregner (hashes) indekset. Hvis der opstår en konflikt, bruger den anden den samme nøgle til at bestemme, hvor langt ned værdien skal indsættes. Der er mere ved dette - se senere.
Perfekt Hash-funktion
En perfekt hash-funktion er en hash-funktion, der ikke kan resultere i nogen kollision. Dette kan ske, når nøglesættet er relativt lille, og hver nøgle kortlægges til et bestemt heltal i hash-tabellen.
I ASCII-tegnsæt kan store bogstaver kortlægges til deres tilsvarende små bogstaver ved hjælp af en hash-funktion. Bogstaver er repræsenteret i computerens hukommelse som tal. I ASCII-tegnsæt er A 65, B er 66, C er 67 osv. og a er 97, b er 98, c er 99 osv. For at kortlægge fra A til a, tilføj 32 til 65; for at kortlægge fra B til b, tilføj 32 til 66; for at kortlægge fra C til c, tilføj 32 til 67; og så videre. Her er store bogstaver nøglerne, og små bogstaver er værdierne. Hashtabellen til dette kan være en matrix, hvis værdier er de tilknyttede indekser. Husk, spande i matrixen kan være tomme. Så spande i matrixen fra 64 til 0 kan være tomme. Hashfunktionen føjer simpelthen 32 til store bogstaver for at få indekset og dermed små bogstaver. En sådan funktion er en perfekt hash-funktion.
Hashing fra heltal til heltal
Der er forskellige metoder til hashing af heltal. En af dem kaldes Modulo Division Method (Function).
Modulo Division Hashing-funktionen
En funktion i computersoftware er ikke en matematisk funktion. I computing (software) består en funktion af et sæt udsagn forud for argumenter. For Modulo Division-funktionen er tasterne heltal og kortlægges til indekser i spandenes række. Nøglesættet er stort, så kun nøgler, der meget sandsynligt forekommer i aktiviteten, vil blive kortlagt. Så kollisioner opstår, når usandsynlige nøgler skal kortlægges.
I erklæringen,
20/6 = 3R2
20 er udbyttet, 6 er deleren, og 3 resten 2 er kvotienten. Resten 2 kaldes også modulo. Bemærk: det er muligt at have en modulo på 0.
Til denne hashing er bordstørrelsen normalt en styrke på 2, f.eks.g. 64 = 26 eller 256 = 28, etc. Deleren til denne hashing-funktion er et primtal tæt på arraystørrelsen. Denne funktion deler nøglen med divisoren og returnerer modulo. Modulet er indekset for spanden. Den tilknyttede værdi i skovlen er en værdi efter eget valg (værdi for nøglen).
Hash-knapper med variabel længde
Her er tasterne til nøglesættet tekster af forskellige længder. Forskellige heltal kan gemmes i hukommelsen ved hjælp af det samme antal bytes (størrelsen på et engelsk tegn er en byte). Når forskellige taster har forskellige bytestørrelser, siges de at have variabel længde. En af metoderne til hashing af variable længder kaldes Radix Conversion Hashing.
Radix konvertering Hashing
I en streng er hvert tegn på computeren et tal. I denne metode,
Hash-kode (indeks) = x0-enk − 1+x1-enk − 2+… + Xk − 2-en1+xk − 1-en0
Hvor (x0, x1,…, xk − 1) er tegnene i inputstrengen, og a er en radix, e.g. 29 (se senere). k er antallet af tegn i strengen. Der er mere ved dette - se senere.
Nøgler og værdier
I et nøgle / værdipar er en værdi muligvis ikke nødvendigvis et tal eller en tekst. Det kan også være en rekord. En post er en liste skrevet vandret. I et nøgle / værdipar refererer hver tast muligvis til en anden tekst eller et andet nummer eller en post.
Associativ matrix
En liste er en datastruktur, hvor listeelementerne er relateret, og der er et sæt operationer, der fungerer på listen. Hvert listeelement kan bestå af et par varer. Den generelle hash-tabel med dens nøgler kan betragtes som en datastruktur, men det er mere et system end en datastruktur. Tasterne og deres tilsvarende værdier er ikke særlig afhængige af hinanden. De er ikke særlig beslægtede med hinanden.
På den anden side er en associativ matrix en lignende ting, men nøgler og deres værdier er meget afhængige af hinanden; de er meget beslægtede med hinanden. For eksempel kan du have et associerende udvalg af frugter og deres farver. Hver frugt har naturligvis sin farve. Frugtens navn er nøglen; farven er værdien. Under indsættelse indsættes hver nøgle med dens værdi. Når du sletter, slettes hver nøgle med sin værdi.
Et associerende array er en hash-tabel datastruktur sammensat af nøgle / værdipar, hvor der ikke er noget duplikat for nøglerne. Værdierne kan have duplikater. I denne situation er tasterne en del af strukturen. Det vil sige, at tasterne skal lagres, mens nøglerne ikke skal gemmes med den generelle hastighedstabel. Problemet med de duplikerede værdier løses naturligvis ved hjælp af indekserne i spandenes række. Forveks ikke mellem duplikerede værdier og kollision ved et indeks.
Da et associerende array er en datastruktur, har det mindst følgende operationer:
Associerende matrixoperationer
indsæt eller tilføj
Dette indsætter et nyt nøgle / værdipar i samlingen og kortlægger nøglen til dens værdi.
omfordele
Denne handling erstatter værdien af en bestemt nøgle til en ny værdi.
slet eller fjern
Dette fjerner en nøgle plus dens tilsvarende værdi.
kig op
Denne handling søger efter værdien på en bestemt nøgle og returnerer værdien (uden at fjerne den).
Konklusion
En hash-tabel datastruktur består af et array og en funktion. Funktionen kaldes en hash-funktion. Funktionen kortlægger nøgler til værdier i arrayet gennem arrayets indekser. Nøglerne skal ikke nødvendigvis være en del af datastrukturen. Nøglesættet er normalt større end de lagrede værdier. Når en kollision opstår, løses den enten ved den separate kædemetode eller den åbne adresseringsmetode. Et associerende array er et specielt tilfælde af hash-tabel datastruktur.


