TensorFlow har fundet enorm anvendelse inden for maskinindlæring, netop fordi maskinindlæring involverer en masse antal knasende og bruges som en generaliseret problemløsningsteknik. Og selvom vi vil interagere med det ved hjælp af Python, har det frontend til andre sprog som Go, Node.js og endda C #.
Tensorflow er som en sort boks, der skjuler alle de matematiske finesser inde i den, og udvikleren kalder bare de rigtige funktioner til at løse et problem. Men hvilket problem?
Machine Learning (ML)
Antag at du designer en bot til at spille et skakspil. På grund af den måde, skak er designet på, hvordan brikkerne bevæger sig, og det veldefinerede mål med spillet, er det meget muligt at skrive et program, der ville spille spillet ekstremt godt. Faktisk ville det overvinde hele menneskeheden i skak. Det ville vide nøjagtigt, hvilket træk det skal foretages i betragtning af tilstanden af alle brikker på tavlen.
Dog kan et sådant program kun spille skak. Spillets regler er bagt ind i kodens logik, og alt det program gør er at udføre den logik nøjagtigt og mere præcist end noget menneske kunne. Det er ikke en generel algoritme, som du kan bruge til at designe en hvilken som helst spilbot.
Med maskinlæring skifter paradigmet, og algoritmerne bliver mere og mere almindelige.
Ideen er enkel, den starter med at definere et klassificeringsproblem. For eksempel vil du automatisere processen med at identificere arten af edderkopper. De arter, som du kender, er de forskellige klasser (ikke at forveksle med taksonomiske klasser), og formålet med algoritmen er at sortere et nyt ukendt billede i en af disse klasser.
Her ville det første skridt for mennesket være at bestemme funktionerne i forskellige individuelle edderkopper. Vi leverer data om længden, bredden, kropsmassen og farven på de enkelte edderkopper sammen med de arter, de tilhører:
| Længde | Bredde | Masse | Farve | Struktur | Arter |
| 5 | 3 | 12 | Brun | glat | Far Lange ben |
| 10 | 8 | 28 | Brun-sort | behåret | Tarantel |
At have en stor samling af sådanne individuelle edderkoppedata vil blive brugt til at 'træne' algoritmen, og et andet lignende datasæt vil blive brugt til at teste algoritmen for at se, hvor godt det klarer sig mod nye oplysninger, det aldrig har stødt på før, men som vi allerede kender svar til.
Algoritmen starter på en randomiseret måde. Det vil sige, hver edderkop uanset dens egenskaber ville blive klassificeret som enhver af arten. Hvis der er 10 forskellige arter i vores datasæt, vil denne naive algoritme få den korrekte klassificering ca. 1/10 af tiden på grund af rent held.
Men så begyndte maskinlæringsaspektet at tage over. Det ville begynde at forbinde visse funktioner med et bestemt resultat. For eksempel er hårede edderkopper sandsynligvis tarantulaer, og det samme er de større edderkopper. Så når en ny edderkop, der er stor og behåret dukker op, får den større sandsynlighed for at være tarantula. Bemærk, at vi stadig arbejder med sandsynligheder, det er fordi vi iboende arbejder med en sandsynlig algoritme.
Læringsdelen fungerer ved at ændre sandsynlighederne. Oprindeligt starter algoritmen ved tilfældigt at tildele enkeltpersoner en 'art' -mærke ved at lave tilfældige korrelationer som at være 'hår' og være 'far lange ben'. Når det foretager en sådan sammenhæng, og træningsdatasættet ikke synes at være enig med det, bortfalder denne antagelse.
Tilsvarende, når en korrelation fungerer godt gennem flere eksempler, bliver den stærkere hver gang. Denne metode til at snuble mod sandheden er bemærkelsesværdig effektiv takket være mange af de matematiske finesser, som du som nybegynder ikke ønsker at bekymre dig om.
TensorFlow og træner din egen Flower Classifier
TensorFlow tager idéen om maskinlæring endnu længere. I ovenstående eksempel var du ansvarlig for at bestemme de funktioner, der adskiller en edderkoppeart fra en anden. Vi var nødt til at måle individuelle edderkopper omhyggeligt og oprette hundreder af sådanne poster.
Men vi kan gøre det bedre ved kun at tilvejebringe rå billeddata til algoritmen, vi kan lade algoritmen finde mønstre og forstå forskellige ting om billedet som at genkende figurerne i billedet og derefter forstå, hvad strukturen på forskellige overflader er, farven , så videre og så videre. Dette er begyndelsestanken om computersyn, og du kan også bruge den til andre slags indgange som lydsignaler og træne din algoritme til stemmegenkendelse. Alt dette kommer under paraplybetegnelsen 'Deep Learning', hvor maskinindlæring tages til sit logiske ekstreme.
Dette generelle sæt opfattelser kan derefter specialiseres, når man beskæftiger sig med mange blomsterbilleder og kategoriserer dem.
I eksemplet nedenfor bruger vi en Python2.7 front-end til interface med TensorFlow, og vi bruger pip (ikke pip3) til at installere TensorFlow. Python 3-understøttelsen er stadig lidt buggy.
For at lave din egen billedklassificering skal vi først bruge TensorFlow ved at installere den ved hjælp af pip:
$ pip installere tensorflowDernæst skal vi klone tensorflow-for-digtere-2 git arkiv. Dette er et rigtig godt sted at starte af to grunde:
- Det er enkelt og let at bruge
- Det kommer til en vis grad foruddannet. For eksempel er blomsterklassifikatoren allerede uddannet til at forstå, hvilken struktur den ser på, og hvilke former den ser på, så den er beregningsmæssigt mindre intensiv.
Lad os få lageret:
$ git klon https: // github.com / googlecodelabs / tensorflow-for-digtere-2$ cd tensorflow-for-digtere-2
Dette bliver vores arbejdskatalog, så alle kommandoer skal udstedes inde fra den, fra nu af.
Vi har stadig brug for at træne algoritmen til det specifikke problem med at genkende blomster, for at vi har brug for træningsdata, så lad os få det:
$ curl http: // download.tensorflow.org / eksempel_billeder / blomsterfotos.tgz| tjære xz -C tf_files
Mappen .. ./tensorflow-for-digtere-2 / tf_files indeholder et ton af disse billeder korrekt mærket og klar til brug. Billederne har to forskellige formål:
- Uddannelse af ML-programmet
- Test af ML-programmet
Du kan kontrollere indholdet af mappen tf_files og her finder du ud af, at vi kun indsnævrer til 5 kategorier af blomster, nemlig tusindfryd, tulipaner, solsikker, mælkebøtte og roser.
Uddannelse af modellen
Du kan starte træningsprocessen ved først at konfigurere følgende konstanter til at ændre størrelsen på alle inputbilleder i en standardstørrelse og bruge en letvægts mobilenetarkitektur:
$ IMAGE_SIZE = 224$ ARCHITECTURE = "mobilenet_0.50 _ $ IMAGE_SIZE "
Påkald derefter python-scriptet ved at køre kommandoen:
$ python -m-scripts.omskole \--flaskehals_dir = tf_filer / flaskehalse \
--how_many_training_steps = 500 \
--model_dir = tf_files / modeller / \
--summaries_dir = tf_files / training_summaries / "$ ARCHITECTURE" \
--output_graph = tf_files / omskoleret_graf.pb \
--output_labels = tf_files / retrained_labels.txt \
--arkitektur = "$ ARCHITECTURE" \
--image_dir = tf_files / flower_photos
Mens der er mange indstillinger, der er angivet her, angiver de fleste af dine inputdatamapper og antallet af iteration samt outputfilerne, hvor oplysningerne om den nye model vil blive gemt. Dette bør ikke tage længere tid end 20 minutter at køre på en middelmådig bærbar computer.
Når scriptet er færdigt med både træning og test, giver det dig et nøjagtighedsestimat af den uddannede model, som i vores tilfælde var lidt højere end 90%.
Brug af den uddannede model
Du er nu klar til at bruge denne model til billedgenkendelse af ethvert nyt billede af en blomst. Vi bruger dette billede:

Solsikkens ansigt er næppe synlig, og dette er en stor udfordring for vores model:
For at få dette billede fra Wikimedia commons skal du bruge wget:
$ wget https: // upload.wikimedia.org / wikipedia / commons / 2/28 / Sunflower_head_2011_G1.jpg$ mv Solsikkehoved_2011_G1.jpg tf_files / ukendt.jpg
Det gemmes som ukendt.jpg under tf_files underkatalog.
Nu for sandhedens øjeblik skal vi se, hvad vores model har at sige om dette billede.For at gøre det påberåber vi os label_image manuskript:
$ python -m-scripts.label_image --graph = tf_files / retrained_graph.pb --billede = tf_files / ukendt.jpg
Du får en output svarende til denne:
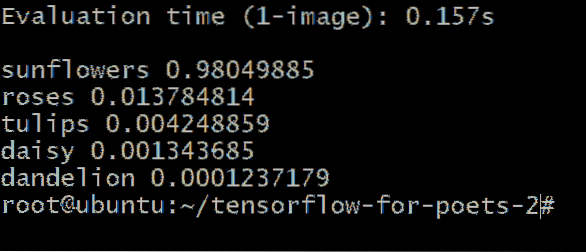
Tallene ved siden af blomstertypen repræsenterer sandsynligheden for, at vores ukendte billede hører til den kategori. For eksempel er det 98.04% er sikre på, at billedet er af en solsikke, og at det kun er 1.37% chance for, at det er en rose.
Konklusion
Selv med meget middelmådige beregningsressourcer ser vi en svimlende nøjagtighed til at identificere billeder. Dette demonstrerer tydeligt kraften og fleksibiliteten ved TensorFlow.
Herfra kan du begynde at eksperimentere med forskellige andre slags input eller prøve at begynde at skrive din egen anden applikation ved hjælp af Python og TensorFlow. Hvis du vil vide, hvordan maskinindlæring fungerer internt, er her en interaktiv måde for dig at gøre det på.


