Hvad er Apache Solr
Apache Solr er en af de mest populære NoSQL-databaser, som kan bruges til at gemme data og forespørge om dem i næsten realtid. Den er baseret på Apache Lucene og er skrevet i Java. Ligesom Elasticsearch understøtter det databaseforespørgsler via REST API'er. Dette betyder, at vi kan bruge enkle HTTP-opkald og bruge HTTP-metoder som GET, POST, PUT, SLET osv. for at få adgang til data. Det giver også en mulighed for at hente data i form af XML eller JSON gennem REST API'erne.
Arkitektur: Apache Solr
Før vi kan begynde at arbejde med Apache Solr, skal vi forstå de komponenter, der udgør Apache Solr. Lad os se på nogle komponenter, den har:
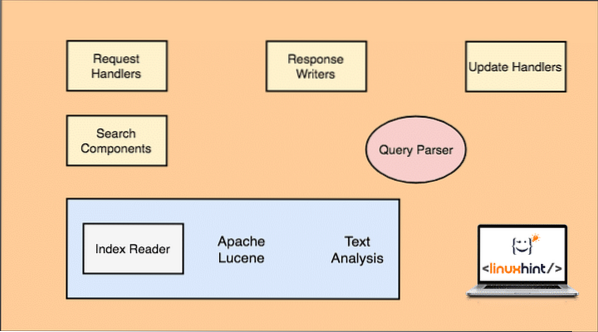
Apache Solr-arkitektur
Bemærk, at kun hovedkomponenter til Solr er vist i ovenstående figur. Lad os også forstå deres funktionalitet her:
- Anmodningshåndterere: De anmodninger, en klient fremsætter til Solr, styres af en anmodningshåndterer. Anmodningen kan være alt fra at tilføje en ny post til at opdatere et indeks i Solr. Handlere identificerer typen af anmodning ud fra HTTP-metoden, der bruges sammen med anmodningstilknytningen.
- Søgningskomponent: Dette er en af de vigtigste komponenter, Solr er kendt for. Søgekomponent tager sig af udførelse af søgerelaterede operationer som fuzziness, stavekontrol, termforespørgsler osv.
- Forespørgselsparser: Dette er den komponent, der faktisk analyserer forespørgslen, som en klient sender til anmodningshåndtereren og opdeler en forespørgsel i flere dele, som kan forstås af den underliggende motor
- Svarforfatter: Denne komponent er ansvarlig for styring af outputformatet for de forespørgsler, der sendes til motoren. Response Writer giver os mulighed for at levere output i forskellige formater som XML, JSON osv.
- Analysator / Tokenizer: Lucene Engine forstår forespørgsler i form af flere tokens. Solr analyserer forespørgslen, deler den i flere tokens og sender den til Lucene Engine.
- Opdater anmodningsprocessor: Når en forespørgsel køres, og den udfører operationer som at opdatere et indeks og data relateret til det, er komponenten Update Request Processor ansvarlig for at administrere dataene i indekset og ændre det.
Kom godt i gang med Apache Solr
For at begynde at bruge Apache Solr skal den være installeret på maskinen. For at gøre dette skal du læse Installer Apache Solr på Ubuntu.
Sørg for, at du har en aktiv Solr-installation, hvis du vil prøve eksempler, vi præsenterer senere i lektionen, og admin-siden er tilgængelig på localhost:
Apache Solr-hjemmeside
Indsættelse af data
For at starte, lad os overveje en samling i Solr, som vi kalder som linux_hint_collection. Der er ikke behov for eksplicit at definere denne samling, som når vi indsætter det første objekt, oprettes samlingen automatisk. Lad os prøve vores første REST API-opkald for at indsætte et nyt objekt i den navngivne samling linux_hint_collection.
Indsættelse af data
curl -X POST -H 'Content-Type: application / json''http: // localhost: 8983 / solr / linux_hint_collection / update / json / docs' --data-binær '
"id": "iduye",
"name": "Shubham"
'
Her er hvad vi kommer tilbage med denne kommando:

Kommando til at indsætte data i Solr
Data kan også indsættes ved hjælp af Solr-hjemmesiden, vi kiggede på tidligere. Lad os prøve dette her, så tingene er klare:
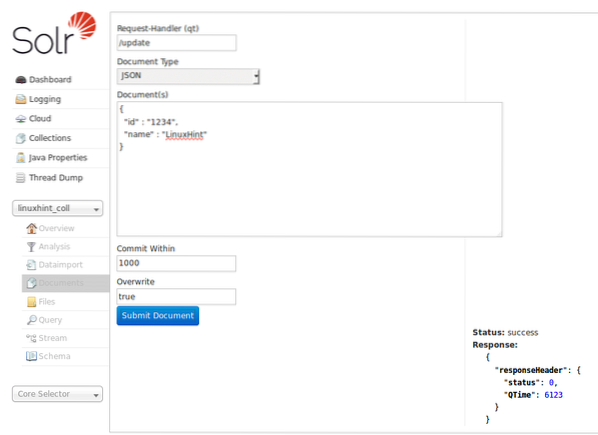
Indsæt data via Solr-hjemmesiden
Da Solr har en glimrende måde at interagere med HTTP RESTful API'er, demonstrerer vi DB-interaktion ved hjælp af de samme API'er fra nu af og vil ikke fokusere meget på at indsætte data via Solr-websiden.
Liste over alle samlinger
Vi kan også liste alle samlinger i Apache Solr ved hjælp af en REST API. Her er kommandoen, vi kan bruge:
Liste over alle samlinger
krølle http: // localhost: 8983 / solr / admin / samlinger?handlinger = LISTE & wt = jsonLad os se output for denne kommando:
Vi ser to samlinger her, der findes i vores Solr-installation.
Få objekt efter ID
Lad os nu se, hvordan vi kan FÅ data fra Solr-indsamling med et specifikt ID. Her er REST API-kommandoen:
Få objekt efter ID
krølle http: // localhost: 8983 / solr / linux_hint_collection / get?id = iduyeHer er hvad vi kommer tilbage med denne kommando:
Få alle data
I vores sidste REST API forespurgte vi data ved hjælp af et specifikt ID. Denne gang får vi alle data til stede i vores Solr-samling.
Få objekt efter ID
krølle http: // localhost: 8983 / solr / linux_hint_collection / select?q = *: *Her er hvad vi kommer tilbage med denne kommando: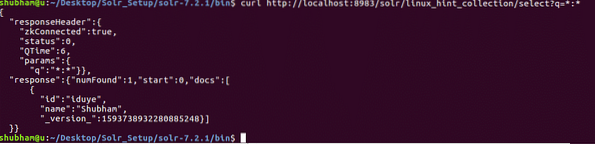
Bemærk, at vi har brugt '*: *' i forespørgselsparameteren. Dette specificerer, at Solr skal returnere alle data, der er til stede i samlingen. Selvom vi har specificeret, at alle data skal returneres, forstår Solr, at samlingen muligvis har en stor mængde data i sig og så, det returnerer kun de første 10 dokumenter.
Sletning af alle data
Indtil nu brugte alle API'er, vi prøvede, et JSON-format. Denne gang vil vi prøve XML-forespørgselsformat. Brug af XML-format ligner meget JSON, da XML også er selvbeskrivende.
Lad os prøve en kommando for at slette alle data, vi har i vores samling.
Sletning af alle data
krølle "http: // localhost: 8983 / solr / linux_hint_collection / update?commit = true "-H" Content-Type: text / xml "--data-binary" *: * "Her er hvad vi kommer tilbage med denne kommando:

Slet alle data ved hjælp af XML-forespørgsel
Hvis vi igen prøver at få alle data, ser vi, at der ikke er nogen data tilgængelige nu:

Få alle data
Samlet antal objekter
For en endelig CURL-kommando, lad os se en kommando, hvormed vi kan finde antallet af objekter, der er til stede i et indeks. Her er kommandoen for det samme:
Samlet antal objekter
krølle http: // localhost: 8983 / solr / linux_hint_collection / query?debug = forespørgsel & q = *: *Her er hvad vi kommer tilbage med denne kommando:
Tæl antal objekter
Konklusion
I denne lektion så vi på, hvordan vi kan bruge Apache Solr og videresende forespørgsler ved hjælp af curl i både JSON- og XML-format. Vi så også, at Solr-adminpanelet er nyttigt på samme måde som alle curl-kommandoer, vi studerede.


