Denne oversigt er lidt abstrakt, så lad os grunde det i et virkeligt scenarie, forestil dig at du har brug for at overvåge flere webservere. Hver kører sit eget websted, og der genereres konstant nye logfiler i hver af dem hvert sekund af dagen. Derudover er der et antal e-mail-servere, som du også skal overvåge.
Det kan være nødvendigt at du gemmer disse data til arkivering og fakturering, hvilket er et batchjob, der ikke kræver øjeblikkelig opmærksomhed. Det kan være en god idé at køre analyser på dataene for at træffe beslutninger i realtid, hvilket kræver nøjagtig og øjeblikkelig input af data. Pludselig befinder du dig i behovet for at strømline dataene på en fornuftig måde til alle de forskellige behov. Kafka fungerer som det abstraktionslag, som flere kilder kan offentliggøre forskellige datastrømme og en given forbruger kan abonnere på de streams, som det finder relevante. Kafka sørger for, at dataene er ordnede. Det er internt i Kafka, som vi har brug for at forstå, inden vi kommer til emnet Partitionering og nøgler.
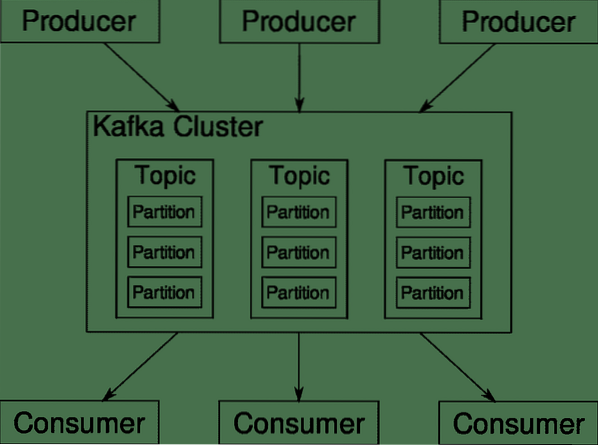
Kafka Emner, mægler og partitioner
Kafka Emner er som tabeller i en database. Hvert emne består af data fra en bestemt kilde af en bestemt type. For eksempel kan din klynges helbred være et emne, der består af oplysninger om CPU og hukommelsesudnyttelse. På samme måde kan indgående trafik til hele klyngen være et andet emne.
Kafka er designet til at være vandret skalerbar. Det vil sige, en enkelt forekomst af Kafka består af flere Kafka mæglere kører på tværs af flere noder, kan hver håndtere datastrømme parallelt med den anden. Selvom nogle få af knudepunkterne fejler, kan din datarørledning fortsætte med at fungere. Et bestemt emne kan derefter opdeles i et antal skillevægge. Denne partitionering er en af de afgørende faktorer bag Kafkas vandrette skalerbarhed.
Mange producenter, datakilder for et givet emne, kan skrive til emnet samtidigt, fordi hver skriver til en anden partition på et hvilket som helst tidspunkt. Nu tildeles normalt data tilfældigt til en partition, medmindre vi giver den en nøgle.
Partitionering og bestilling
Bare for at opsummere skriver producenter data til et givet emne. Dette emne er faktisk opdelt i flere partitioner. Og hver partition lever uafhængigt af de andre, selv for et givet emne. Dette kan føre til en masse forvirring, når ordren til data betyder noget. Måske har du brug for dine data i en kronologisk rækkefølge, men at have flere partitioner til din datastream garanterer ikke perfekt bestilling.
Du kan kun bruge en enkelt partition pr. Emne, men det besejrer hele formålet med Kafka's distribuerede arkitektur. Så vi har brug for en anden løsning.
Nøgler til skillevægge
Data fra en producent sendes tilfældigt til partitioner, som vi nævnte før. Beskeder er de faktiske klumper af data. Hvad producenter kan ud over blot at sende beskeder er at tilføje en nøgle, der følger med den.
Alle meddelelser, der følger med den specifikke nøgle, går til den samme partition. Så for eksempel kan en brugers aktivitet spores kronologisk, hvis brugerens data er mærket med en nøgle, og så ender de altid i en partition. Lad os kalde denne partition p0 og brugeren u0.
Partition p0 henter altid de u0-relaterede meddelelser, fordi den nøgle binder dem sammen. Men det betyder ikke, at p0 kun er bundet med det. Det kan også tage beskeder fra u1 og u2, hvis det har kapacitet til at gøre det. Tilsvarende kan andre partitioner forbruge data fra andre brugere.
Det punkt, at en given brugers data ikke er spredt over forskellige partitioner, der sikrer kronologisk rækkefølge for den bruger. Det overordnede emne for brugerdata, kan stadig udnytte den distribuerede arkitektur af Apache Kafka.
Konklusion
Mens distribuerede systemer som Kafka løser nogle ældre problemer som manglende skalerbarhed eller har et enkelt fejlpunkt. De kommer med et sæt problemer, der er unikke for deres eget design. Forudse disse problemer er et vigtigt job for enhver systemarkitekt. Ikke kun det, nogle gange er du virkelig nødt til at lave en cost-benefit-analyse for at afgøre, om de nye problemer er en værdig kompromis for at slippe af med de ældre. Bestilling og synkronisering er bare toppen af isbjerget.
Forhåbentlig kan artikler som disse og den officielle dokumentation hjælpe dig undervejs.


