For eksempel, hvis du ønsker at få regelmæssige opdateringer om dine yndlingsprodukter til rabattilbud, eller du vil automatisere processen med at downloade episoder af din yndlingssæson en efter en, og hjemmesiden ikke har nogen API til det, så er det eneste valg du sidder tilbage med er webskrabning.Webskrabning kan være ulovligt på nogle websteder, afhængigt af om et websted tillader det eller ej. Hjemmesider bruger “robotter.txt ”-fil til eksplicit at definere webadresser, der ikke må skrottes. Du kan kontrollere, om webstedet tillader det eller ikke ved at tilføje “robotter.txt ”med websteds domænenavn. For eksempel https: // www.google.com / robotter.txt
I denne artikel bruger vi Python til skrabning, fordi det er meget nemt at konfigurere og bruge. Det har mange indbyggede biblioteker og tredjepartsbiblioteker, der kan bruges til skrabning og organisering af data. Vi bruger to Python-biblioteker “urllib” til at hente websiden og “BeautifulSoup” til at analysere websiden for at anvende programmeringshandlinger.
Sådan fungerer Web Scraping?
Vi sender en anmodning til websiden, hvorfra du vil skrabe dataene. Hjemmesiden vil svare på anmodningen med HTML-indhold på siden. Derefter kan vi analysere denne webside til BeautifulSoup til videre behandling. For at hente websiden bruger vi "urllib" -biblioteket i Python.
Urllib downloader websideindholdet i HTML. Vi kan ikke anvende strengoperationer på denne HTML-webside til indholdsudvinding og viderebehandling. Vi bruger et Python-bibliotek "BeautifulSoup", der analyserer indholdet og udtrækker de interessante data.
Skrabning af artikler fra Linuxhint.com
Nu hvor vi har en idé om, hvordan webskrabning fungerer, lad os gøre noget. Vi forsøger at skrabe artikeltitler og links fra Linuxhint.com. Så åbn https: // linuxhint.com / i din browser.
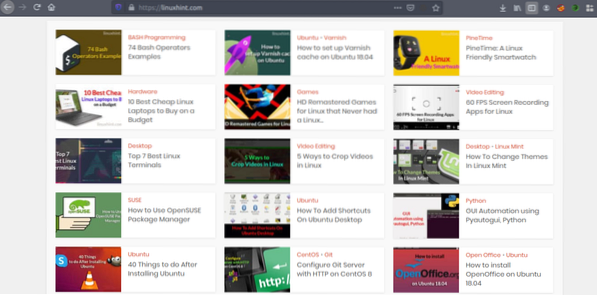
Tryk nu på CRTL + U for at se HTML-kildekoden på websiden.
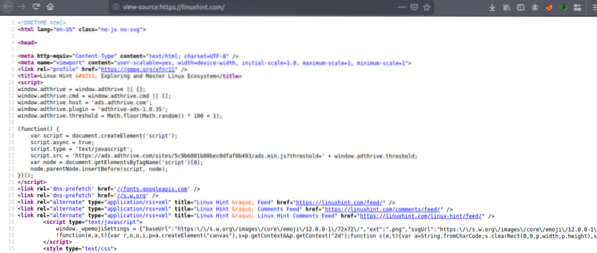
Kopier kildekoden, og gå til https: // htmlformatter.com / for at pretificere koden. Efter prettifikation af koden er det let at inspicere koden og finde interessante oplysninger.
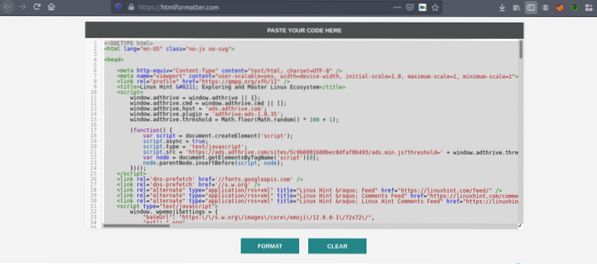
Kopier nu igen den formaterede kode og indsæt den i din yndlings teksteditor som atom, sublim tekst osv. Nu skraber vi de interessante oplysninger ved hjælp af Python. Skriv følgende
// Installer smukt suppebibliotek, urllib kommerforudinstalleret i Python
ubuntu @ ubuntu: ~ $ sudo pip3 installer bs4
ubuntu @ ubuntu: ~ $ python3
Python 3.7.3 (standard, 7. okt 2019, 12:56:13)
[GCC 8.3.0] på linux
Skriv “hjælp”, “ophavsret”, “kreditter” eller “licens” for at få flere oplysninger.
// Importer urllib>>> import urllib.anmodning
// Importér BeautifulSoup
>>> fra bs4 import BeautifulSoup
// Indtast den URL, du vil hente
>>> my_url = 'https: // linuxhint.com / '
// Anmod om URL-websiden ved hjælp af urlopen-kommandoen
>>> klient = urllib.anmodning.urlopen (min_url)
// Gem HTML-websiden i variablen “html_page”
>>> html_page = klient.Læs()
// Luk URL-forbindelsen efter hentning af websiden
>>> klient.tæt()
// parse HTML-websiden til BeautifulSoup til skrabning
>>> page_soup = BeautifulSoup (html_page, "html.parser ")
Lad os nu se på HTML-kildekoden, vi lige har kopieret og indsat for at finde ting af interesse.
Du kan se, at den første artikel, der er anført på Linuxhint.com hedder "74 Bash Operators Eksempler", find dette i kildekoden. Det er lukket mellem header tags, og dets kode er
title = "74 Bash Operators Eksempler"> 74 Bash Operators
Eksempler
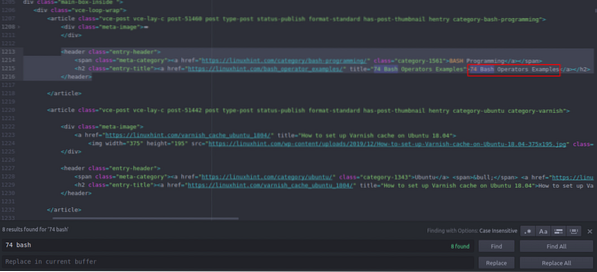
Den samme kode gentages igen og igen med ændringen af kun artikeltitler og links. Den næste artikel har følgende HTML-kode
title = "Sådan opsættes Varnish cache på Ubuntu 18.04 ">
Sådan oprettes Varnish-cache på Ubuntu 18.04
Du kan se, at alle artikler inklusive disse to er lukket i det samme “
”Tag og brug den samme klasse“ entry-title ”. Vi kan bruge "findAll" -funktionen i det smukke suppebibliotek til at finde og liste ned alle "”Med klasse“ entry-title ”. Skriv følgende i din Python-konsol // Denne kommando finder alle “”Tagelementer med klasse navngivet
“Entry-title”. Outputtet gemmes i en matrix.
>>> artikler = side_suppe.findAll ("h2" ,
"class": "entry-title")
// Antallet af artikler, der findes på forsiden af Linuxhint.com
>>> len (artikler)
102
// Først ekstraheret “”Tagelement, der indeholder artikelnavn og link
>>> artikler [0]
title = "74 Eksempler på bashoperatører">
74 Eksempler på Bash-operatører
// Andet ekstraheret “”Tagelement, der indeholder artikelnavn og link
>>> artikler [1]
title = "Sådan opsættes Varnish cache på Ubuntu 18.04 ">
Sådan oprettes Varnish-cache på Ubuntu 18.04
// Vis kun tekst i HTML-tags ved hjælp af tekstfunktion
>>> artikler [1].tekst
'Sådan opsættes Varnish-cache på Ubuntu 18.04 '
”Tagelementer med klasse navngivet
“Entry-title”. Outputtet gemmes i en matrix.
>>> artikler = side_suppe.findAll ("h2" ,
"class": "entry-title")
// Antallet af artikler, der findes på forsiden af Linuxhint.com
>>> len (artikler)
102
// Først ekstraheret “”Tagelement, der indeholder artikelnavn og link
>>> artikler [0]
title = "74 Eksempler på bashoperatører">
74 Eksempler på Bash-operatører
// Andet ekstraheret “”Tagelement, der indeholder artikelnavn og link
>>> artikler [1]
title = "Sådan opsættes Varnish cache på Ubuntu 18.04 ">
Sådan oprettes Varnish-cache på Ubuntu 18.04
// Vis kun tekst i HTML-tags ved hjælp af tekstfunktion
>>> artikler [1].tekst
'Sådan opsættes Varnish-cache på Ubuntu 18.04 '
>>> artikler [0]
title = "74 Eksempler på bashoperatører">
74 Eksempler på Bash-operatører
// Andet ekstraheret “
”Tagelement, der indeholder artikelnavn og link
>>> artikler [1]
title = "Sådan opsættes Varnish cache på Ubuntu 18.04 ">
Sådan oprettes Varnish-cache på Ubuntu 18.04
// Vis kun tekst i HTML-tags ved hjælp af tekstfunktion
>>> artikler [1].tekst
'Sådan opsættes Varnish-cache på Ubuntu 18.04 '
title = "Sådan opsættes Varnish cache på Ubuntu 18.04 ">
Sådan oprettes Varnish-cache på Ubuntu 18.04
Nu hvor vi har en liste over alle 102 HTML “
”Tagelementer, der indeholder artikellink og artikeltitel. Vi kan udtrække både artiklens links og titler. At udtrække links fra “”Tags, kan vi bruge følgende kode // Den følgende kode udtrækker linket fra først tagelement
>>> for link i artikler [0].find_all ('a', href = True):
... udskriv (link ['href'])
..
https: // linuxhint.com / bash_operator_eksempler /
Nu kan vi skrive en for-løkke, der gentager sig gennem alle “
”Tagelement i listen” artikler ”og udtræk artiklelink og titel. >>> for i inden for rækkevidde (0,10):
... print (artikler [i].tekst)
... til link i artikler [i].find_all ('a', href = True):
... udskriv (link ['href'] + "\ n")
..
74 Eksempler på Bash-operatører
https: // linuxhint.com / bash_operator_eksempler /
Sådan oprettes Varnish-cache på Ubuntu 18.04
https: // linuxhint.com / lak_cache_ubuntu_1804 /
PineTime: Et Linux-venligt Smartwatch
https: // linuxhint.com / pinetime_linux_smartwatch /
10 bedste billige Linux-bærbare computere at købe på et budget
https: // linuxhint.com / best_cheap_linux_laptops /
HD Remastered-spil til Linux, der aldrig havde en Linux-udgivelse ..
https: // linuxhint.com / hd_remastered_games_linux /
60 FPS-skærmoptagelsesapps til Linux
https: // linuxhint.com / 60_fps_screen_recording_apps_linux /
74 Eksempler på Bash-operatører
https: // linuxhint.com / bash_operator_eksempler /
... klip ..
På samme måde gemmer du disse resultater i en JSON- eller CSV-fil.
Konklusion
Dine daglige opgaver er ikke kun filhåndtering eller udførelse af systemkommandoer. Du kan også automatisere webrelaterede opgaver som filautomatiseringsautomatisering eller dataekstraktion ved at skrabe internettet i Python. Denne artikel var begrænset til kun simpel dataudtrækning, men du kan udføre enorm opgaveautomatisering ved hjælp af "urllib" og "BeautifulSoup".
>>> for link i artikler [0].find_all ('a', href = True):
... udskriv (link ['href'])
..
https: // linuxhint.com / bash_operator_eksempler /
... print (artikler [i].tekst)
... til link i artikler [i].find_all ('a', href = True):
... udskriv (link ['href'] + "\ n")
..
74 Eksempler på Bash-operatører
https: // linuxhint.com / bash_operator_eksempler /
Sådan oprettes Varnish-cache på Ubuntu 18.04
https: // linuxhint.com / lak_cache_ubuntu_1804 /
PineTime: Et Linux-venligt Smartwatch
https: // linuxhint.com / pinetime_linux_smartwatch /
10 bedste billige Linux-bærbare computere at købe på et budget
https: // linuxhint.com / best_cheap_linux_laptops /
HD Remastered-spil til Linux, der aldrig havde en Linux-udgivelse ..
https: // linuxhint.com / hd_remastered_games_linux /
60 FPS-skærmoptagelsesapps til Linux
https: // linuxhint.com / 60_fps_screen_recording_apps_linux /
74 Eksempler på Bash-operatører
https: // linuxhint.com / bash_operator_eksempler /
... klip ..

