Der er også en mulighed for at gemme et grafdesign offline, så det nemt kan eksporteres. Der er mange andre funktioner, der gør brugen af biblioteket meget let:
- Gem grafer til offline brug som vektorgrafik, der er meget optimeret til udskrivnings- og publikationsformål
- De eksporterede diagrammer er i JSON-format og ikke billedformat. Denne JSON kan nemt indlæses i andre visualiseringsværktøjer som Tableau eller manipuleres med Python eller R
- Da de eksporterede grafer er af JSON-karakter, er det praktisk talt meget nemt at integrere disse diagrammer i en webapplikation
- Plotly er et godt alternativ til Matplotlib til visualisering
For at begynde at bruge Plotly-pakken skal vi registrere en konto på det tidligere nævnte websted for at få et gyldigt brugernavn og API-nøgle, hvormed vi kan begynde at bruge dens funktioner. Heldigvis er der en gratis prisplan for Plotly, som vi får nok funktioner til at lave produktionskort.
Installation af Plotly
Bare en note, før du starter, kan du bruge et virtuelt miljø til denne lektion, som vi kan lave med følgende kommando:
python -m virtualenv plottetkilde numpy / bin / aktiver
Når det virtuelle miljø er aktivt, kan du installere Plotly-biblioteket i den virtuelle env, så eksempler, vi opretter næste, kan udføres:
pip installere plottetVi bruger Anaconda og Jupyter i denne lektion. Hvis du vil installere det på din maskine, skal du se på lektionen, der beskriver “Sådan installeres Anaconda Python på Ubuntu 18.04 LTS ”og del din feedback, hvis du står over for problemer. For at installere Plotly med Anaconda skal du bruge følgende kommando i terminalen fra Anaconda:
conda install -c plotly plotlyVi ser noget som dette, når vi udfører ovenstående kommando:
Når alle de nødvendige pakker er installeret og færdige, kan vi komme i gang med at bruge Plotly-biblioteket med følgende importerklæring:
importer plottetNår du har oprettet en konto på Plotly, skal du bruge to ting - brugernavnet på kontoen og en API-nøgle. Der kan kun være en API-nøgle, der hører til hver konto. Så hold det sikkert et sted, som om du mister det, du bliver nødt til at regenerere nøglen, og alle gamle applikationer, der bruger den gamle nøgle, holder op med at arbejde.
I alle de Python-programmer, du skriver, skal du nævne legitimationsoplysningerne som følger for at begynde at arbejde med Plotly:
plottet.værktøjer.set_credentials_file (brugernavn = 'brugernavn', api_key = 'din-api-nøgle')Lad os komme i gang med dette bibliotek nu.
Kom godt i gang med Plotly
Vi bruger følgende import i vores program:
importer pandaer som pdimporter numpy som np
importer scipy som sp
importer plottet.plottet som py
Vi gør brug af:
- Pandaer til effektiv læsning af CSV-filer
- NumPy til enkle tabeloperationer
- Scipy til videnskabelige beregninger
- Plotly til visualisering
For nogle af eksemplerne vil vi gøre brug af Plotlys egne datasæt, der er tilgængelige på Github. Endelig skal du være opmærksom på, at du også kan aktivere offline-tilstand for Plotly, når du har brug for at køre Plotly-scripts uden en netværksforbindelse:
importer pandaer som pdimporter numpy som np
importer scipy som sp
importer plottet
plottet.offline.init_notebook_mode (forbundet = sand)
importer plottet.offline som py
Du kan køre følgende erklæring for at teste Plotly-installationen:
print (plottet).__version__)Vi ser noget som dette, når vi udfører ovenstående kommando:

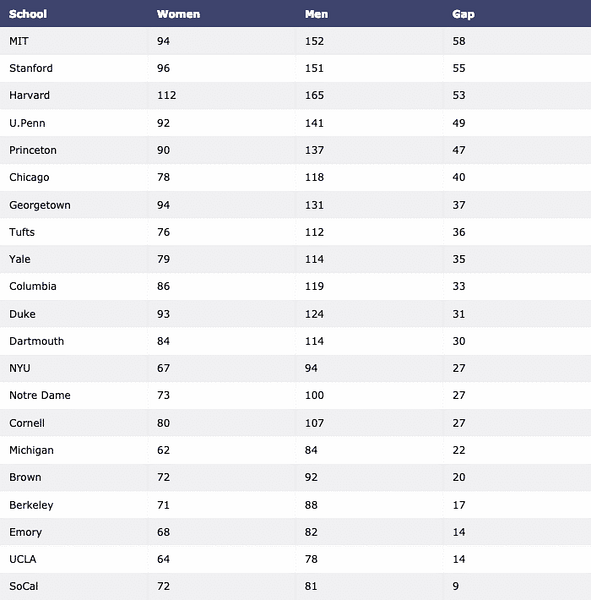
Vi downloader endelig datasættet med Pandas og visualiserer det som en tabel:
importer plottet.figur_fabrik som ffdf = pd.read_csv ("https: // rå.githubusercontent.com / plotly / datasæt / master / school_
indtjening.csv ")
tabel = ff.create_table (df)
py.iplot (tabel, filnavn = 'tabel')
Vi ser noget som dette, når vi udfører ovenstående kommando:
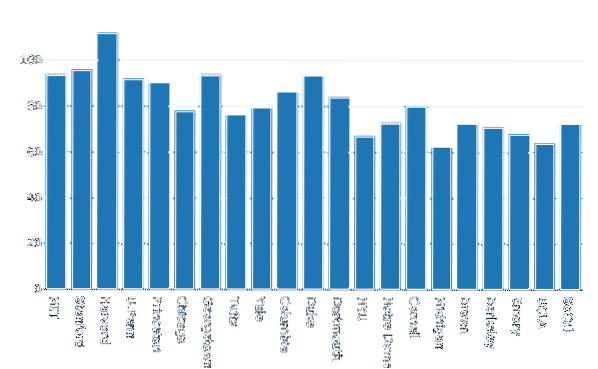
Lad os nu konstruere en Søjlediagram at visualisere dataene:
importer plottet.graph_objs as godata = [gå.Bar (x = df.Skole, y = df.Kvinder)]
py.iplot (data, filnavn = 'kvinder-bar')
Vi ser noget som dette, når vi udfører ovenstående kodestykke:
Når du ser ovenstående diagram med Jupyter-notesbog, vil du blive præsenteret med forskellige muligheder for at zoome ind / ud over et bestemt afsnit af diagrammet, Box & Lasso select og meget mere.
Grupperede søjlediagrammer
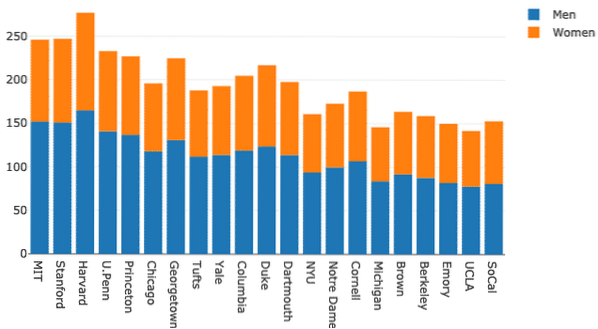
Flere søjlediagrammer kan grupperes sammen til sammenligningsformål meget let med Plotly. Lad os bruge samme datasæt til dette og vise variation af mænds og kvinders tilstedeværelse på universiteter:
kvinder = gå.Bar (x = df.Skole, y = df.Kvinder)mænd = gå.Bar (x = df.Skole, y = df.Mænd)
data = [mænd, kvinder]
layout = gå.Layout (barmode = "gruppe")
fig = gå.Figur (data = data, layout = layout)
py.iplot (fig)
Vi ser noget som dette, når vi udfører ovenstående kodestykke:

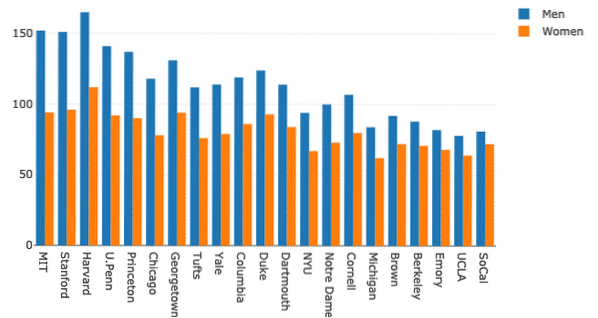
Selvom dette ser godt ud, er etiketterne i øverste højre hjørne ikke korrekte! Lad os rette dem:
kvinder = gå.Bar (x = df.Skole, y = df.Kvinder, navn = "Kvinder")mænd = gå.Bar (x = df.Skole, y = df.Mænd, navn = "Mænd")
Grafen ser meget mere beskrivende ud nu:
Lad os prøve at ændre barmode:
layout = gå.Layout (barmode = "relativ")fig = gå.Figur (data = data, layout = layout)
py.iplot (fig)
Vi ser noget som dette, når vi udfører ovenstående kodestykke:
Pie-diagrammer med Plotly
Nu vil vi forsøge at konstruere et cirkeldiagram med Plotly, der etablerer en grundlæggende forskel mellem procentdelen af kvinder på tværs af alle universiteter. Navnene på universiteterne vil være etiketterne, og de faktiske tal vil blive brugt til at beregne procentdelen af helheden. Her er kodestykket for det samme:
spor = gå.Tærte (etiketter = df.Skole, værdier = df.Kvinder)py.iplot ([trace], filnavn = 'pie')
Vi ser noget som dette, når vi udfører ovenstående kodestykke:
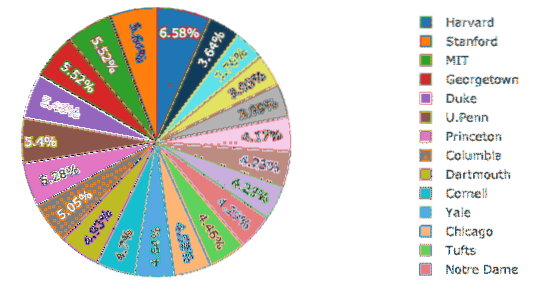
Den gode ting er, at Plotly kommer med mange funktioner ved at zoome ind og ud og mange andre værktøjer til at interagere med det konstruerede diagram.
Tidsseriedatavisualisering med Plotly
Visualisering af tidsseriedata er en af de vigtigste opgaver, der kommer på tværs, når du er en dataanalytiker eller en dataingeniør.
I dette eksempel bruger vi et separat datasæt i det samme GitHub-arkiv, da de tidligere data ikke involverede nogen tidsstemplede data specifikt. Som her vil vi plotte variation af Apples markedsbeholdning over tid:
finansiel = pd.read_csv ("https: // rå.githubusercontent.com / plotly / datasæt / master /finans-diagrammer-æble.csv ")
data = [gå.Scatter (x = økonomisk.Dato, y = økonomisk ['AAPL.Tæt'])]
py.iplot (data)
Vi ser noget som dette, når vi udfører ovenstående kodestykke:
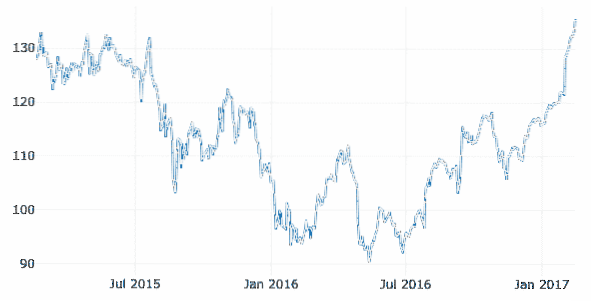
Når du holder musen over grafvariationslinjen, kan du specificere punktoplysninger:

Vi kan også bruge zoom ind og ud knapper til at se data, der er specifikke for hver uge.
OHLC-diagram
Et OHLC-diagram (Open High Low close) bruges til at vise variation af en enhed over et tidsrum. Dette er let at konstruere med PyPlot:
fra datetime import datetimeopen_data = [33.0, 35.3, 33.5, 33.0, 34.1]
high_data = [33.1, 36.3, 33.6, 33.2, 34.8]
lave_data = [32.7, 32.7, 32.8, 32.6, 32.8]
close_data = [33.0, 32.9, 33.3, 33.1, 33.1]
datoer = [datetime (år = 2013, måned = 10, dag = 10),
datetime (år = 2013, måned = 11, dag = 10),
datetime (år = 2013, måned = 12, dag = 10),
datetime (år = 2014, måned = 1, dag = 10),
datetime (år = 2014, måned = 2, dag = 10)]
spor = gå.Ohlc (x = datoer,
open = open_data,
høj = høj_data,
lav = lav_data,
close = close_data)
data = [spor]
py.iplot (data)
Her har vi givet nogle eksempler på datapunkter, der kan udledes som følger:
- De åbne data beskriver aktiekursen, når markedet blev åbnet
- De høje data beskriver den højeste aktierate opnået gennem en given tidsperiode
- De lave data beskriver den laveste lagerkapacitet, der er opnået gennem en given tidsperiode
- De tætte data beskriver den afsluttende aktiekurs, når et givet tidsinterval var overstået
Lad os nu køre det kodestykke, vi har angivet ovenfor. Vi ser noget som dette, når vi udfører ovenstående kodestykke:
Dette er en fremragende sammenligning af, hvordan man fastlægger tidssammenligninger for en enhed med sin egen og sammenligner den med dens høje og lave præstationer.
Konklusion
I denne lektion kiggede vi på et andet visualiseringsbibliotek, Plotly, som er et glimrende alternativ til Matplotlib i produktionskvalitetsapplikationer, der er eksponeret som webapplikationer, Plotly er et meget dynamisk og funktionsrige bibliotek til brug til produktionsformål, så dette er bestemt en færdighed, vi skal have under vores bælte.
Find al kildekoden, der blev brugt i denne lektion, på Github. Del din feedback på lektionen på Twitter med @sbmaggarwal og @LinuxHint.

