I denne lektion er det, hvad vi agter at gøre. Vi finder ud af, hvordan værdier for forskellige HTML-tags kan udvindes, og tilsidesætter også standardfunktionaliteten i dette modul for at tilføje nogle egne logik. Vi gør dette ved hjælp af HTMLParser klasse i Python i html.parser modul. Lad os se koden i aktion.
Ser man på HTMLParser klasse
For at analysere HTML-tekst i Python kan vi gøre brug af HTMLParser klasse i html.parser modul. Lad os se på klasse dfinition for HTMLParser klasse:
klasse html.parser.HTMLParser (*, convert_charrefs = True)Det convert_charrefs felt, hvis indstillet til Sand, vil alle tegnreferencer blive konverteret til deres Unicode-ækvivalenter. Kun den script / stil elementer konverteres ikke. Nu vil vi forsøge at forstå hver funktion for denne klasse også for bedre at forstå, hvad hver funktion gør.
- handle_startendtag Dette er den første funktion, der udløses, når HTML-streng sendes til klasseinstansen. Når teksten når her, overføres kontrollen til andre funktioner i klassen, som indsnævres til andre tags i strengen. Dette er også klart i definitionen for denne funktion: def handle_startendtag (self, tag, attrs):
selv.handle_starttag (tag, attrs)
selv.handle_endtag (tag) - handle_starttag: Denne metode administrerer startkoden for de data, den modtager. Dens definition er som vist nedenfor: def handle_starttag (self, tag, attrs):
passere - handle_endtag: Denne metode administrerer slutkoden for de data, den modtager: def handle_endtag (self, tag):
passere - handle_charref: Denne metode styrer karakterhenvisningerne i de data, den modtager. Dens definition er som vist nedenfor: def handle_charref (selv, navn):
passere - handle_entityref: Denne funktion håndterer enhedshenvisningerne i HTML'en, der sendes til den: def handle_entityref (selv, navn):
passere - handle_data: Dette er den funktion, hvor der arbejdes rigtigt med at udtrække værdier fra HTML-tags og sendes data relateret til hvert tag. Dens definition er som vist nedenfor: def handle_data (self, data):
passere - håndtag_kommentar: Ved hjælp af denne funktion kan vi også få kommentarer knyttet til en HTML-kilde: def handle_comment (self, data):
passere - handle_pi: Da HTML også kan have behandlingsinstruktioner, er dette den funktion, hvor disse Dens definition er som vist nedenfor: def handle_pi (selv, data):
passere - håndtag_decl: Denne metode håndterer erklæringerne i HTML, dens definition gives som: def handle_decl (self, decl):
passere
Underklassificering af HTMLParser-klassen
I dette afsnit vil vi underklasse HTMLParser-klassen og se på nogle af de funktioner, der kaldes, når HTML-data sendes til klasseinstans. Lad os skrive et simpelt script, der gør alt dette:
fra html.parser importerer HTMLParserklasse LinuxHTMLParser (HTMLParser):
def handle_starttag (selv, tag, attrs):
print ("Start tag stødt på:", tag)
def handle_endtag (selv, tag):
udskriv ("Slut tag fundet:", tag)
def handle_data (selv, data):
print ("Data fundet:", data)
parser = LinuxHTMLParser ()
parser.foder("
''
Python HTML-parsingsmodul
')
Her er hvad vi kommer tilbage med denne kommando:
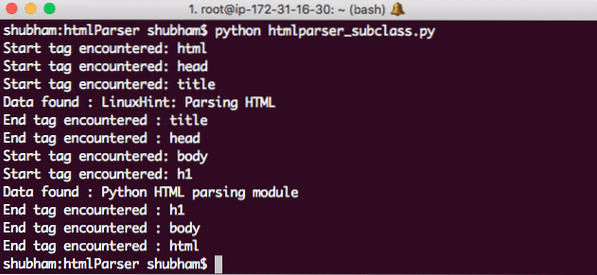
Python HTMLParser-underklasse
HTMLParser-funktioner
I dette afsnit arbejder vi med forskellige funktioner i HTMLParser-klassen og ser på funktionaliteten for hver af disse:
fra html.parser importerer HTMLParserfra html.enheder importerer name2codepoint
klasse LinuxHint_Parse (HTMLParser):
def handle_starttag (selv, tag, attrs):
print ("Start tag:", tag)
til attr i attrs:
print ("attr:", attr)
def handle_endtag (selv, tag):
print ("End tag:", tag)
def handle_data (selv, data):
print ("Data:", data)
def handle_comment (selv, data):
print ("Kommentar:", data)
def handle_entityref (selv, navn):
c = chr (name2codepoint [navn])
print ("Navngivet ent:", c)
def handle_charref (selv, navn):
hvis navn.starter med ('x'):
c = chr (int (navn [1:], 16))
andet:
c = chr (int (navn))
print ("Num ent:", c)
def handle_decl (selv, data):
print ("Decl:", data)
parser = LinuxHint_Parse ()
Lad os med forskellige opkald føde separate HTML-data til denne forekomst og se, hvilket output disse opkald genererer. Vi starter med et simpelt DOCTYPE snor:
parser.foder(''"http: // www.w3.org / TR / html4 / streng.dtd "> ')Her er hvad vi kommer tilbage med dette opkald:
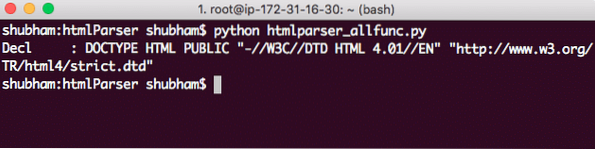
DOCTYPE streng
Lad os nu prøve et billedkode og se, hvilke data det udtrækker:
parser.foder(' ')
') Her er hvad vi kommer tilbage med dette opkald:

HTMLParser-billedkode
Lad os derefter prøve, hvordan script-tag opfører sig med Python-funktioner:
parser.foder('')parser.foder('')
parser.feed ('# python color: green')
Her er hvad vi kommer tilbage med dette opkald:

Script-tag i htmlparser
Endelig videresender vi også kommentarer til HTMLParser-sektionen:
parser.foder('''''')
Her er hvad vi kommer tilbage med dette opkald:

Analysering af kommentarer
Konklusion
I denne lektion kiggede vi på, hvordan vi kan analysere HTML ved hjælp af Pythons egen HTMLParser-klasse uden noget andet bibliotek. Vi kan let ændre koden for at ændre kilden til HTML-data til en HTTP-klient.
Læs flere Python-baserede indlæg her.


