Pandaer til numerisk analyse
Pandas blev udviklet ud fra behovet for en effektiv måde at administrere økonomiske data i Python på. Pandas er et bibliotek, der kan importeres til python for at hjælpe med at manipulere og transformere numeriske data. Wes McKinney startede projektet i 2008. Pandas ledes nu af en gruppe ingeniører og understøttes af NUMFocus nonprofit, som vil sikre dets fremtidige vækst og udvikling. Det betyder, at pandaer vil være et stabilt bibliotek i mange år og kan medtages i dine applikationer uden bekymring for et lille projekt.
Selvom pandas oprindeligt blev udviklet til at modellere økonomiske data, kan dets datastrukturer bruges til at manipulere en række numeriske data. Pandas har et antal datastrukturer, der er indbyggede og kan bruges til let at modellere og manipulere numeriske data. Denne vejledning dækker pandaer DataFrame datastruktur i dybden.
Hvad er en DataFrame?
EN DataFrame er en af de primære datastrukturer i pandaer og repræsenterer en 2-D-indsamling af data. Der er mange analoge objekter til denne type 2-D-datastruktur, hvoraf nogle inkluderer det stadigt populære Excel-regneark, en databasetabel eller et 2-D-array, der findes på de fleste programmeringssprog. Nedenfor er et eksempel på en DataFrame i et grafisk format. Det repræsenterer en gruppe af tidsserier med aktielukningskurser efter dato.
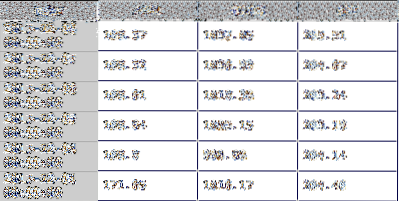
Denne vejledning fører dig gennem mange af metoderne i datarammen, og jeg vil bruge en finansiel model fra den virkelige verden til at demonstrere disse funktioner.
Importerer data
Pandaklasser har nogle indbyggede metoder til at hjælpe med at importere data til en datastruktur. Nedenfor er et eksempel på, hvordan man importerer data til et pandapanel med Datalæser klasse. Det kan bruges til at importere data fra flere gratis økonomiske datakilder, herunder Quandl, Yahoo Finance og Google. For at kunne bruge pandabiblioteket skal du tilføje det som en import i din kode.
importer pandaer som pdNedenstående metode starter programmet ved at køre metoden til selvstudie.
hvis __name__ == "__main__":tutorial_run ()
Det tutorial_run metoden er nedenfor. Det er den næste metode, jeg vil tilføje til koden. Den første linje i denne metode definerer en liste over aktiekort. Denne variabel vil blive brugt senere i koden som en liste over lagre, som data vil blive anmodet om for at udfylde DataFrame. Den anden kodelinje kalder get_data metode. Som vi vil se, get_data metoden tager tre parametre som input. Vi videregiver listen over aktiemærker, startdato og slutdato for de data, som vi vil anmode om.
def tutorial_run ():# Aktiekort til kilde fra Yahoo Finance
symboler = ['SPY', 'AAPL', 'GOOG']
#get data
df = get_data (symboler, '2006-01-03', '2017-12-31')
Nedenfor definerer vi get_data metode. Som jeg nævnte ovenfor tager det tre parametre en liste over symboler, en start- og slutdato.
Den første kodelinje definerer et pandapanel ved at starte en Datalæser klasse. Opkaldet til Datalæser klasse opretter forbindelse til Yahoo Finance-serveren og anmoder om de daglige høje, lave, tætte og justerede lukkeværdier for hver af aktierne i symboler liste. Disse data indlæses i et panelobjekt af pandaer.
EN panel er en 3-D matrix og kan betragtes som en "stak" af DataFrames. Hver DataFrame i stakken indeholder en af de daglige værdier for de bestande og anmodede datointervaller. For eksempel nedenstående DataFrame, præsenteret tidligere, er slutkursen DataFrame fra anmodningen. Hver type pris (høj, lav, tæt og justeret luk) har sin egen DataFrame i det resulterende panel returneret fra anmodningen.
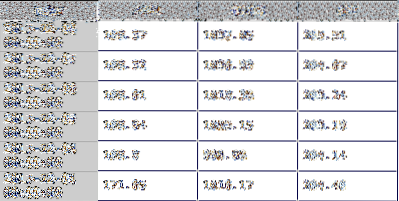
Den anden linje kode skiver panelet i en enkelt DataFrame og tildeler de resulterende data til df. Dette vil være min variabel for DataFrame som jeg bruger resten af selvstudiet. Det holder daglige tætværdier for de tre aktier i det angivne datointerval. Panelet skæres ved at specificere hvilket af panelet DataFrames du vil gerne vende tilbage. I dette eksempel på kodelinjen nedenfor er det 'Luk'.
Når vi har vores DataFrame på plads vil jeg dække nogle af de nyttige funktioner i pandabiblioteket, der giver os mulighed for at manipulere dataene i DataFrame objekt.
def get_data (symboler, startdato, slutdato):panel = data.DataReader (symboler, 'yahoo', startdato, slutdato)
df = panel ['Luk']
udskrive (df.hoved (5))
udskrive (df.hale (5))
returner df
Hoved og haler
Den tredje og fjerde linje i get_data udskrive datahovedets funktionshoved og hale. Jeg finder dette mest nyttigt til fejlfinding og visualisering af dataene, men det kan også bruges til at vælge den første eller sidste prøve af dataene i DataFrame. Hoved- og hale-funktionen trækker den første og sidste række data fra DataFrame. Heltalsparameteren mellem parenteserne definerer antallet af rækker, der skal vælges ved metoden.
.lok
Det DataFrame lok metoden skiver DataFrame efter indeks. Nedenstående linje med kode skiver df DataFrame af indekset 12-12-2017. Jeg har givet et skærmbillede af nedenstående resultater.
udskriv df.loc ["12-12-2017"]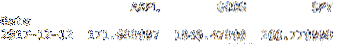
lok kan også bruges som et todimensionelt stykke. Den første parameter er rækken, og den anden parameter er kolonnen. Koden nedenfor returnerer en enkelt værdi, der svarer til slutkursen for Apple den 12/12/2014.
udskriv df.loc ["12-12-2017", "AAPL"]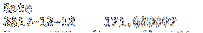
Det lok metode kan bruges til at skære alle rækker i en kolonne eller alle kolonner i en række. Det : operatør bruges til at betegne alle. Nedenstående kodelinje vælger alle rækkerne i kolonnen til Google-lukkepriser.
udskriv df.loc [:, "GOOG"]
.fillna
Det er almindeligt, især i økonomiske datasæt, at have NaN-værdier i din DataFrame. Pandas giver en funktion til at udfylde disse værdier med en numerisk værdi. Dette er nyttigt, hvis du ønsker at udføre en slags beregning af de data, der kan være skæv eller mislykkes på grund af NaN-værdierne.
Det .fillna metode erstatter den angivne værdi for hver NaN-værdi i dit datasæt. Nedenstående kodelinje udfylder hele NaN i vores DataFrame med et 0. Denne standardværdi kan ændres for en værdi, der opfylder behovet for det datasæt, du arbejder med, ved at opdatere den parameter, der sendes til metoden.
df.fillna (0)Normalisering af data
Når du bruger algoritmer til maskinlæring eller økonomisk analyse, er det ofte nyttigt at normalisere dine værdier. Nedenstående metode er en effektiv beregning til normalisering af data i en panda DataFrame. Jeg opfordrer dig til at bruge denne metode, fordi denne kode kører mere effektivt end andre metoder til normalisering og kan vise store præstationsforøgelser på store datasæt.
.iloc er en metode, der ligner .lok men tager placeringsbaserede parametre i stedet for de tagbaserede parametre. Det tager et nulbaseret indeks snarere end kolonnenavnet fra .lok eksempel. Nedenstående normaliseringskode er et eksempel på nogle af de kraftige matrixberegninger, der kan udføres. Jeg vil springe over den lineære algebra-lektion, men i det væsentlige deler denne kodelinje hele matrixen eller DataFrame efter den første værdi i hver tidsserie. Afhængigt af dit datasæt vil du muligvis have en norm baseret på min, max eller gennemsnit. Disse normer kan også let beregnes ved hjælp af nedenstående matrixbaserede stil.
def normaliser_data (df):returner df / df.iloc [0 ,:]
Plotte data
Når du arbejder med data, er det ofte nødvendigt at repræsentere dem grafisk. Plottemetoden giver dig mulighed for nemt at oprette en graf ud fra dine datasæt.
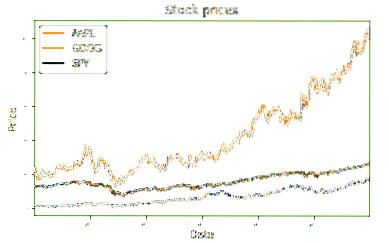
Metoden nedenfor tager vores DataFrame og tegner det på en standard linjediagram. Metoden tager en DataFrame og en titel som parametre. Den første linje med kodesæt økse til et plot af DataFrame df. Dens indstiller titel og skriftstørrelse for teksten. De følgende to linjer indstiller etiketterne til x- og y-aksen. Den sidste kodelinje kalder showmetoden, der udskriver grafen til konsollen. Jeg har givet et skærmbillede af resultaterne fra plottet nedenfor. Dette repræsenterer de normaliserede slutkurser for hver af aktierne i den valgte tidsperiode.
def plot_data (df, title = "Aktiekurser"):økse = df.plot (titel = titel, skrifttype = 2)
økse.set_xlabel ("Date")
økse.set_ylabel ("Pris")
grund.at vise()
Pandas er et robust databehandlingsbibliotek. Det kan bruges til forskellige typer data og præsenterer et kortfattet og effektivt sæt metoder til at manipulere dit datasæt. Nedenfor har jeg givet den fulde kode fra vejledningen, så du kan gennemgå og ændre for at imødekomme dine behov. Der er et par andre metoder, der hjælper dig med datamanipulation, og jeg opfordrer dig til at gennemgå de pandadokumenter, der er lagt ud på nedenstående referencesider. NumPy og MatPlotLib er to andre biblioteker, der fungerer godt for datavidenskab og kan bruges til at forbedre kraften i pandasbiblioteket.
Fuld kode
importer pandaer som pddef plot_selected (df, columns, start_index, end_index):
plot_data (df.ix [start_index: end_index, kolonner])
def get_data (symboler, startdato, slutdato):
panel = data.DataReader (symboler, 'yahoo', startdato, slutdato)
df = panel ['Luk']
udskrive (df.hoved (5))
udskrive (df.hale (5))
udskriv df.loc ["12-12-2017"]
udskriv df.loc ["12-12-2017", "AAPL"]
udskriv df.loc [:, "GOOG"]
df.fillna (0)
returner df
def normaliser_data (df):
returner df / df.ix [0 ,:]
def plot_data (df, title = "Aktiekurser"):
økse = df.plot (titel = titel, skrifttype = 2)
økse.set_xlabel ("Date")
økse.set_ylabel ("Pris")
grund.at vise()
def tutorial_run ():
#Vælg symboler
symboler = ['SPY', 'AAPL', 'GOOG']
#get data
df = get_data (symboler, '2006-01-03', '2017-12-31')
plot_data (df)
hvis __name__ == "__main__":
tutorial_run ()
Referencer
Pandas startside
Panda Wikipedia-side
https: // da.wikipedia.org / wiki / Wes_McKinney
NumFocus Startside


