- 1 for sand eller
- 0 for falsk
Den vigtigste betydning af logistisk regression:
- De uafhængige variabler må ikke være multikollinearitet; hvis der er noget forhold, så skal det være meget lidt.
- Datasættet til den logistiske regression skal være stort nok til at få bedre resultater.
- Kun disse attributter skal være der i datasættet, hvilket har en eller anden betydning.
- De uafhængige variabler skal være i overensstemmelse med log odds.
At bygge modellen af Logistisk regression, vi bruger scikit-lær bibliotek. Processen med den logistiske regression i python er angivet nedenfor:
- Importer alle de nødvendige pakker til logistisk regression og andre biblioteker.
- Upload datasættet.
- Forstå de uafhængige datasætvariabler og afhængige variabler.
- Opdel datasættet i trænings- og testdata.
- Initialiser den logistiske regressionsmodel.
- Tilpas modellen med træningsdatasættet.
- Forudsig modellen ved hjælp af testdataene og beregn nøjagtigheden af modellen.
Problem: De første trin er at indsamle det datasæt, som vi vil anvende Logistisk regression. Datasættet, som vi skal bruge her, er til MS-optagelsesdatasættet. Dette datasæt har fire variabler, hvoraf tre er uafhængige variabler (GRE, GPA, work_experience), og den ene er en afhængig variabel (optaget). Dette datasæt fortæller, om kandidaten får adgang til et prestigefyldt universitet eller ej baseret på deres GPA, GRE eller arbejdsoplevelse.
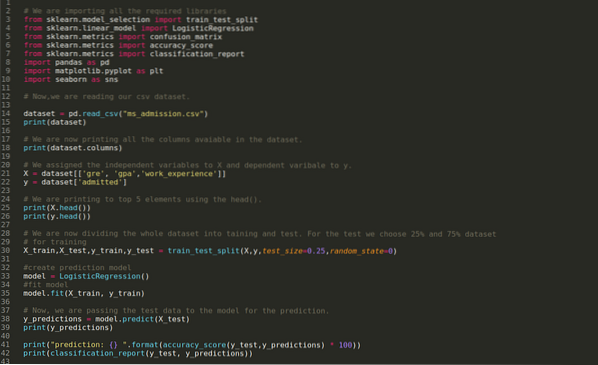
Trin 1: Vi importerer alle de nødvendige biblioteker, som vi har brug for til python-programmet.
Trin 2: Nu indlæser vi vores ms adgangsdatasæt ved hjælp af read_csv pandas-funktionen.

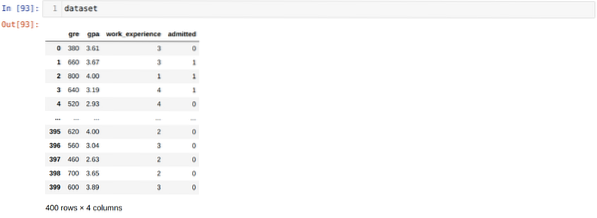
Trin 3: Datasættet ser ud som nedenfor:
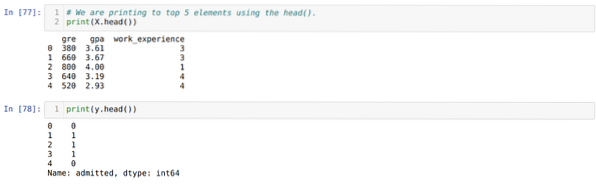
Trin 4: Vi kontrollerer alle de tilgængelige kolonner i datasættet og indstiller derefter alle uafhængige variabler til variabel X og afhængige variabler til y, som vist i nedenstående skærmbillede.

Trin 5: Efter at have indstillet de uafhængige variabler til X og den afhængige variabel til y, udskriver vi nu her for at krydstjekke X og y ved hjælp af hovedpandafunktionen.
Trin 6: Nu skal vi opdele hele datasættet i træning og test. Til dette bruger vi train_test_split-metoden til sklearn. Vi har givet 25% af hele datasættet til testen og de resterende 75% af datasættet til træningen.
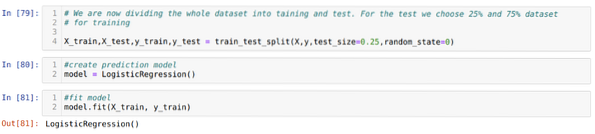
Trin 7: Nu skal vi opdele hele datasættet i træning og test. Til dette bruger vi train_test_split-metoden til sklearn. Vi har givet 25% af hele datasættet til testen og de resterende 75% af datasættet til træningen.
Derefter opretter vi Logistic Regression-modellen og passer til træningsdataene.
Trin 8: Nu er vores model klar til forudsigelse, så vi sender nu testdata (X_test) til modellen og fik resultaterne. Resultaterne viser (y_forudsigelser), at værdierne 1 (godkendt) og 0 (ikke godkendt).

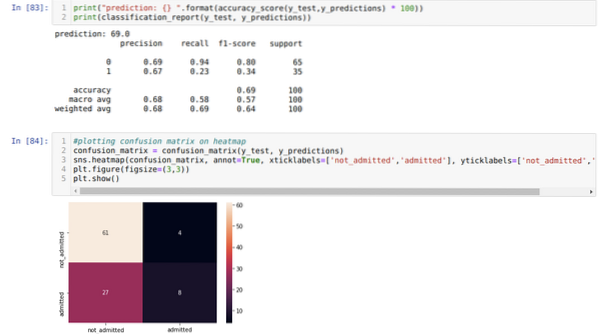
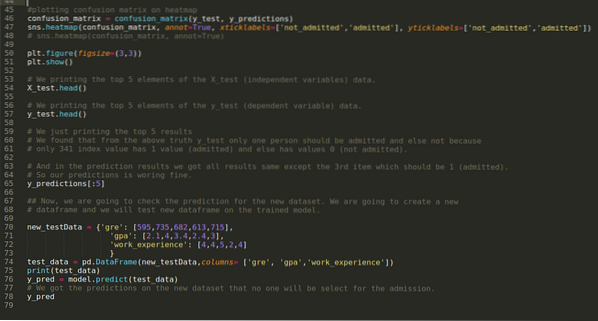
Trin 9: Nu udskriver vi klassifikationsrapporten og forvirringsmatrixen.
Klassifikationsrapporten viser, at modellen kan forudsige resultaterne med en nøjagtighed på 69%.
Forvirringsmatrixen viser de samlede X_test-dataoplysninger som:
TP = ægte positive = 8
TN = ægte negative = 61
FP = falske positive = 4
FN = falske negativer = 27
Så den samlede nøjagtighed i henhold til confusion_matrix er:
Nøjagtighed = (TP + TN) / Total = (8 + 61) / 100 = 0.69
Trin 10: Nu skal vi krydstjekke resultatet gennem udskrivning. Så vi udskriver bare de øverste 5 elementer i X_test og y_test (faktisk ægte værdi) ved hjælp af head pandas-funktionen. Derefter udskriver vi også de 5 bedste resultater af forudsigelserne som vist nedenfor:
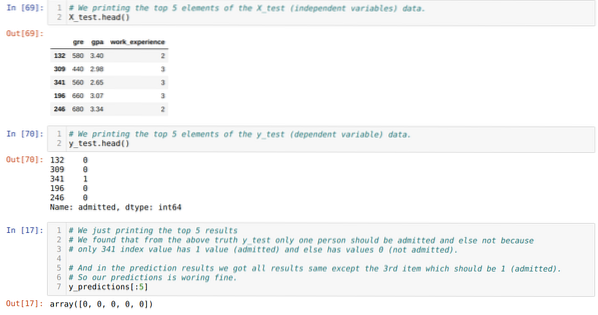
Vi kombinerer alle tre resultater i et ark for at forstå forudsigelserne som vist nedenfor. Vi kan se, at bortset fra 341 X_test-data, som var sandt (1), er forudsigelsen falsk (0) ellers. Så vores model forudsigelser fungerer 69%, som vi allerede har vist ovenfor.

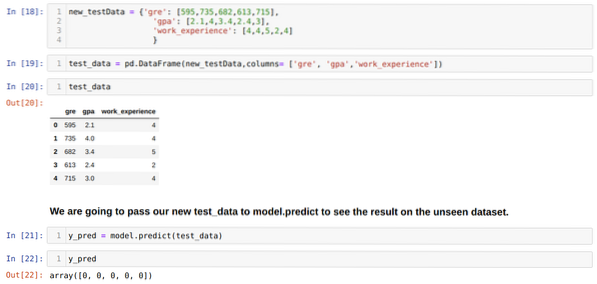
Trin 11: Så vi forstår, hvordan modelforudsigelserne udføres på det usete datasæt som X_test. Så vi oprettede bare et tilfældigt nyt datasæt ved hjælp af en pandas dataframe, sendte det til den uddannede model og fik resultatet vist nedenfor.
Den komplette kode i python angivet nedenfor:
Koden til denne blog sammen med datasættet er tilgængelig på følgende link
https: // github.com / shekharpandey89 / logistisk-regression


