dd-funktioner
"Dd" kan bruges til forskellige formål:
- Ved hjælp af "dd" er det muligt at læse direkte og / eller skrive fra / til forskellige filer, forudsat at funktionen allerede er implementeret i de respekterede drivere.
- Det er super nyttigt til formål som at sikkerhedskopiere opstartssektoren, opnå tilfældige data osv.
- Datakonvertering, for eksempel konvertering af ASCII til EBCDIC-kodning.
dd brug
Her er nogle af de mest almindelige og interessante anvendelser af "dd". Selvfølgelig er "dd" langt mere i stand end disse ting. Hvis du er interesseret, anbefaler jeg altid at tjekke andre dybdegående ressourcer på "dd".
Beliggenhed
hvilken dd
Som output indikerer, når den kører “dd”, starter den fra “/ usr / bin / dd”.
Grundlæggende brug
Her er strukturen, som "dd" følger.
dd hvis =Lad os f.eks. Oprette en fil med tilfældige data. Der er nogle indbyggede specialfiler i Linux, der vises som normale filer som "/ dev / zero", der producerer en kontinuerlig strøm af NULL, "/ dev / random", der producerer kontinuerlige tilfældige data.
dd hvis = / dev / urandom af = ~ / Desktop / tilfældig.txt bs = 1M antal = 5
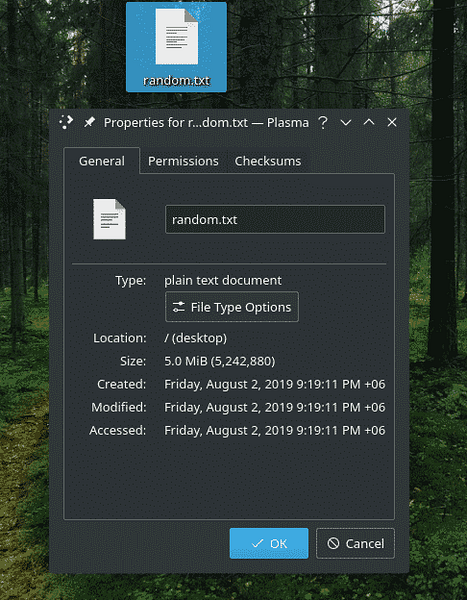
De allerførste muligheder er selvforklarende. Det betyder at bruge “/ dev / urandom” som en datakilde og “~ / Desktop / random.txt ”som destination. Hvad er de andre muligheder?
Her står "bs" for "blokstørrelse". Når dd skriver data, skriver det i blokke. Ved hjælp af denne mulighed kan blokstørrelsen defineres. I dette tilfælde siger værdien “1M”, at blokstørrelsen er 1 megabyte.
"Count" bestemmer antallet af blokke, der skal skrives. Hvis det ikke er rettet, fortsætter “dd” skriveprocessen, medmindre inputstrømmen slutter. I dette tilfælde vil "/ dev / urandom" fortsætte med at generere data uendeligt, så denne mulighed var altafgørende i dette eksempel.
Backup af data
Ved hjælp af denne metode kan "dd" bruges til at dumpe dataene på et helt drev! Alt hvad du behøver er at fortælle drevet som kilde.
dd hvis =
Hvis du går efter sådanne handlinger, skal du sørge for, at din kilde ikke er et bibliotek. “Dd” har ingen idé om, hvordan man behandler en mappe, så tingene fungerer ikke.

"Dd" ved kun, hvordan man arbejder med filer. Så hvis du har brug for sikkerhedskopiering af en mappe, skal du først bruge tar til at arkivere den og derefter bruge "dd" til at overføre den til en fil.
tar cvJf demo.tjære.xz DemoDir /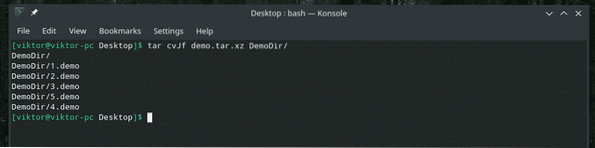

I det næste eksempel udfører vi en meget følsom handling: sikkerhedskopiering af MBR! Hvis dit system nu bruger MBR (Master Boot Record), er det placeret ved de første 512 bytes på systemdisken: 466 bytes til bootloaderen, andre til partitionstabellen.
Kør denne kommando til sikkerhedskopiering af MBR-posten.
dd hvis = / dev / sda af = ~ / Desktop / mbr.img bs = 512 count = 1
Datagendannelse
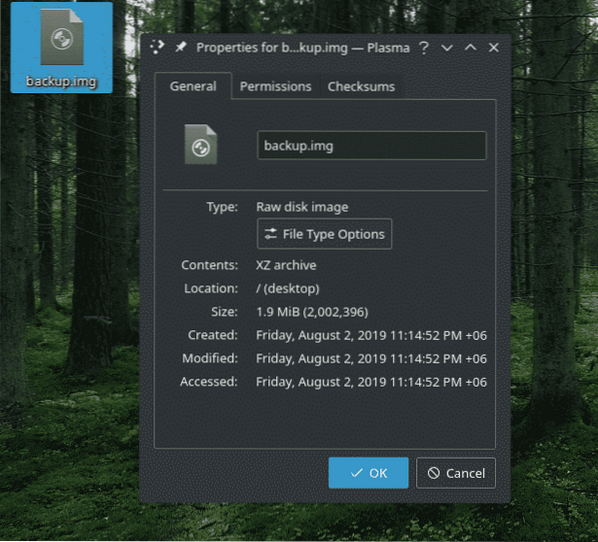
For enhver sikkerhedskopiering er det nødvendigt at gendanne dataene. I tilfælde af "dd" er gendannelsesprocessen lidt anderledes end andre værktøjer. Du er nødt til at omskrive sikkerhedskopifilen på en lignende mappe / partition / enhed.
For eksempel har jeg denne “backup.img-fil, der indeholder "demo.tjære.xz ”-fil. For at udtrække det brugte jeg følgende kommando.
dd if = backup.img af = demo.tjære.xz
Igen skal du sørge for, at du skriver output til en fil. "Dd" er ikke godt med mapper, husk?
Tilsvarende, hvis “dd” blev brugt til at oprette en sikkerhedskopi af en partition, ville gendannelse af den kræve følgende kommando.
dd hvis =
For eksempel hvad med at gendanne den MBR, vi sikkerhedskopierede tidligere?
dd hvis = mbr.img af = / dev / sda
"Dd" muligheder
På et eller andet tidspunkt i denne vejledning stod du over for nogle "dd" -muligheder som "bs" og "count", højre? Der er flere af dem. Her er en liste over, hvad de er, og hvordan man bruger dem.
- obs: Bestemmer størrelsen på data, der skal skrives ad gangen. Standardværdien er 512 byte.

- cbs: Bestemmer størrelsen på de data, der skal konverteres ad gangen.

- ibs: Bestemmer størrelsen på data, der skal læses ad gangen.
- optælling: Kopier kun N-blokke

- søg: Spring N-blokke over ved starten af output

- spring: Spring N-blokke over ved starten af input







Yderligere muligheder:
- nocreat: Opret ikke outputfilen
- notruc: Afkort ikke outputfilen
- noerror: Fortsæt operationen, selv efter du står over for en fejl
- fdatasync: Skriv data til det fysiske lager før processen er færdig
- fsync: Svarende til fdatasync, men skriver også metadataene
- iflag: Tweak operationen baseret på forskellige flag. Tilgængelige flag inkluderer: tilføj til Tilføj data til output

Yderligere muligheder:
- bibliotek: Når et bibliotek står over for, mislykkes handlingen
- dsync: Synkroniseret I / O til data
- sync: Svarende til dsync, men inkluderer metadata
- nocache: Anmodninger om at droppe cache.
- nofollow: Følg ikke nogen symlink

Yderligere muligheder:
- count_bytes: Svarende til "count = N"
- seek_bytes: Svarende til "seek = N"
- skip_bytes: Svarende til "skip = N"
Som du har set, er det muligt at stable flere flag og indstillinger i en enkelt "dd" -kommando for at finjustere funktionsmåden.
dd if = demo.txt af = demo1.txt bs = 10 count = 100 conv = ebcdiciflag = tilføj, nocache, nofollow, sync

Afsluttende tanker
Workflowet af "dd" er ret simpelt. For at "dd" virkelig skal skinne, er det dog op til dig. Der er mange måder kreative måder "dd" kan bruges til at udføre kloge interaktioner.
For detaljerede oplysninger om “dd” og alle dens muligheder, se manden og infosiden.
mand dd

