I denne artikel vil jeg vise dig, hvordan du installerer og bruger CURL på Ubuntu 18.04 Bionic Beaver. Lad os komme igang.
Installation af CURL
Opdater først pakkeopbevaringscachen på din Ubuntu-maskine med følgende kommando:
$ sudo apt-get opdatering
Pakkeopbevaringscachen skal opdateres.
CURL er tilgængelig i den officielle pakkeopbevaring af Ubuntu 18.04 Bionic Beaver.
Du kan køre følgende kommando for at installere CURL på Ubuntu 18.04:
$ sudo apt-get install krølle
CURL skal installeres.
Brug af CURL
I dette afsnit af artiklen vil jeg vise dig, hvordan du bruger CURL til forskellige HTTP-relaterede opgaver.
Kontrol af en URL med CURL
Du kan kontrollere, om en URL er gyldig eller ikke med CURL.
Du kan køre følgende kommando for at kontrollere, om en URL for eksempel https: // www.google.com er gyldigt eller ej.
$ curl https: // www.google.com
Som du kan se fra skærmbilledet nedenfor, vises mange tekster på terminalen. Det betyder URL https: // www.google.com er gyldigt.
Jeg kørte følgende kommando bare for at vise dig, hvordan en dårlig URL ser ud.
$ curl http: // notfound.ikke fundet
Som du kan se fra skærmbilledet nedenfor, står der Kunne ikke løse værten. Det betyder, at URL'en ikke er gyldig.
Download af en webside med CURL
Du kan downloade en webside fra en URL ved hjælp af CURL.
Formatet for kommandoen er:
$ curl -o FILENAME URLHer er FILENAME navnet eller stien til den fil, hvor du vil gemme den downloadede webside. URL er placeringen eller adressen på websiden.
Lad os sige, at du vil downloade den officielle webside for CURL og gemme den som curl-officiel.html-fil. Kør følgende kommando for at gøre det:
$ curl -o curl-officiel.html https: // krølle.haxx.se / docs / httpscripting.html
Websiden downloades.

Som du kan se fra output af ls-kommandoen, er websiden gemt i curl-official.html-fil.

Du kan også åbne filen med en webbrowser, som du kan se på skærmbilledet nedenfor.
Download af en fil med CURL
Du kan også downloade en fil fra internettet ved hjælp af CURL. CURL er en af de bedste download-filer til kommandolinjefiler. CURL understøtter også genoptagne downloads.
Formatet for CURL-kommandoen til download af en fil fra internettet er:
$ krølle -O FILE_URLHer er FILE_URL linket til den fil, du vil downloade. Indstillingen -O gemmer filen med det samme navn, som den er på den eksterne webserver.
Lad os for eksempel sige, at du vil downloade kildekoden til Apache HTTP-server fra internettet med CURL. Du kører følgende kommando:
$ curl -O http: // www-eu.apache.org / dist // httpd / httpd-2.4.29.tjære.gz
Filen downloades.

Filen downloades til den aktuelle arbejdsmappe.

Du kan se det markerede afsnit af output fra kommandoen ls, http-2.4.29.tjære.gz-fil, jeg lige har downloadet.

Hvis du vil gemme filen med et andet navn end den på den eksterne webserver, skal du bare køre kommandoen som følger.
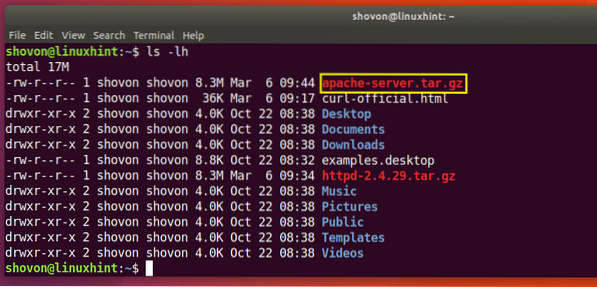
$ curl -o apache-server.tjære.gz http: // www-eu.apache.org / dist // httpd / httpd-2.4.29.tjære.gz
Downloadingen er færdig.

Som du kan se fra det markerede afsnit af output fra ls-kommandoen nedenfor, gemmes filen i et andet navn.
Genoptager downloads med CURL
Du kan også genoptage mislykkede downloads med CURL. Dette er, hvad der gør CURL til en af de bedste downloadlinjer til kommandolinjer.
Hvis du brugte -O mulighed for at downloade en fil med CURL, og den mislykkedes, kører du følgende kommando for at genoptage den igen.
$ curl -C - -O DIN_DOWNLOAD_LINKHer er YOUR_DOWNLOAD_LINK URL'en til den fil, du forsøgte at downloade med CURL, men den mislykkedes.
Lad os sige, at du forsøgte at downloade Apache HTTP Server-kildearkiv, og dit netværk blev afbrudt halvvejs, og du vil genoptage downloadet igen.
Kør følgende kommando for at genoptage download med CURL:
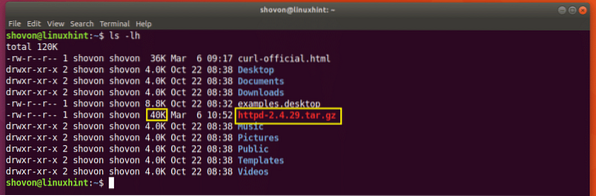
$ curl -C - -O http: // www-eu.apache.org / dist // httpd / httpd-2.4.29.tjære.gz
Downloadet genoptages.

Hvis du har gemt filen med et andet navn end det på den eksterne webserver, skal du køre kommandoen som følger:
$ curl -C - -o FILENAME DOWNLOAD_LINKHer er FILENAME navnet på den fil, du definerede til download. Husk, at FILENAME skal matche det filnavn, du forsøgte at gemme downloadet, da downloadet mislykkedes.
Begræns downloadhastigheden med CURL
Du har muligvis en enkelt internetforbindelse tilsluttet den Wi-Fi-router, som alle i din familie eller på kontoret bruger. Hvis du downloader en stor fil med CURL, kan andre medlemmer af det samme netværk have problemer, når de prøver at bruge internettet.
Du kan begrænse downloadhastigheden med CURL, hvis du vil.
Formatet for kommandoen er:
$ curl - grænsehastighed DOWNLOAD_SPEED -O DOWNLOAD_LINKHer er DOWNLOAD_SPEED den hastighed, hvormed du vil downloade filen.
Lad os sige, at du vil have downloadhastigheden til at være 10 KB, kør følgende kommando for at gøre det:
$ curl - grænsehastighed 10K -O http: // www-eu.apache.org / dist // httpd / httpd-2.4.29.tjære.gz
Som du kan se, begrænses hastigheden til 10 kilo byte (KB), hvilket svarer til næsten 10000 byte (B).

Få HTTP-headeroplysninger ved hjælp af CURL
Når du arbejder med REST API'er eller udvikler websteder, skal du muligvis kontrollere HTTP-overskrifterne for en bestemt URL for at sikre, at din API eller dit websted sender de ønskede HTTP-overskrifter. Du kan gøre det med CURL.
Du kan køre følgende kommando for at få headeroplysningerne om https: // www.google.com:
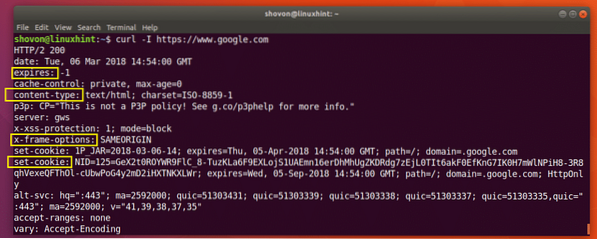
$ curl -Jeg https: // www.google.com
Som du kan se fra skærmbilledet nedenfor, er alle HTTP-svaroverskrifter på https: // www.google.com er angivet.
Sådan installerer og bruger du CURL på Ubuntu 18.04 Bionic Beaver. Tak, fordi du læste denne artikel.


