I denne artikel vil vi udforske forskellige dataplottingmetoder ved hjælp af Pandas python. Vi har udført alle eksempler på pycharm-kildekodeditoren ved hjælp af matplotlib.pyplot-pakke.
Planlægning i Pandas Python
I Pandaer, .plot () har flere parametre, som du kan bruge baseret på dine behov. Ved hjælp af parameteren 'kind' kan du for det meste definere, hvilken type plot du vil oprette.
Syntaksen til plotning af data ved hjælp af Pandas Python
Følgende syntaks bruges til at plotte en DataFrame i Pandas Python:
# import af pandaer og matplotlib.pyplot-pakkerimporter pandaer som pd
importer matplotlib.pyplot som plt
# Forbered data for at oprette DataFrame
data_frame =
'Kolonne1': ['felt1', 'felt2', 'felt3', 'felt4', ...],
'Kolonne2': ['felt1', 'felt2', 'felt3', 'felt4', ...]
var_df = pd.DataFrame (data_frame, columns = ['Column1', 'Column2])
print (variabel)
# plotte søjlediagram
var_df.grund.bar (x = 'Kolonne1', y = 'Kolonne2')
plt.at vise()
Du kan også definere plot-typen ved hjælp af parameteren kind som følger:
var_df.plot (x = 'Kolonne1', y = 'Kolonne2', slags = 'bar')Pandas DataFrames-objekter har følgende plotmetoder til plotning:
- Spredningsplanlægning: grund.sprede()
- Bar plotning: grund.bar (), plot.barh () hvor h repræsenterer vandrette bjælker.
- Linjeplotting: grund.linje ()
- Plottning af tærter: grund.pie()
Hvis en bruger kun bruger plot () -metoden uden at bruge nogen parameter, opretter den standardlinjediagrammet.
Vi vil nu uddybe nogle hovedtyper af tegning i detaljer ved hjælp af nogle eksempler.
Spredningsplanlægning i pandaer
I denne type af tegning har vi repræsenteret forholdet mellem to variabler. Lad os tage et eksempel.
Eksempel
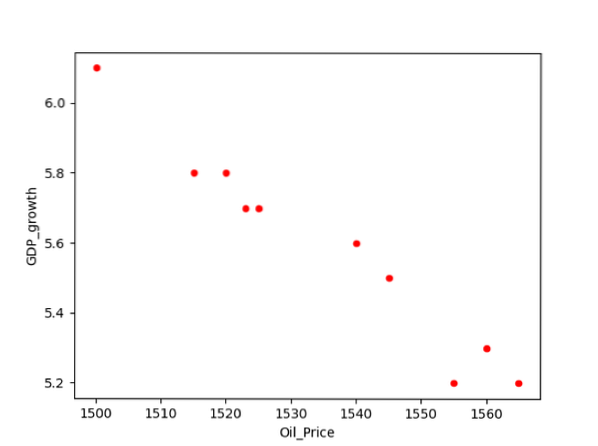
For eksempel har vi data om sammenhæng mellem to variabler GDP_growth og Oil_price. For at plotte forholdet mellem to variabler har vi udført følgende stykke kode på vores kildekodeditor:
importer matplotlib.pyplot som pltimporter pandaer som pd
gdp_cal = pd.DataFrame (
'GDP_growth': [6.1, 5.8, 5.7, 5.7, 5.8, 5.6, 5.5, 5.3, 5.2, 5.2],
'Oliepris': [1500, 1520, 1525, 1523, 1515, 1540, 1545, 1560, 1555, 1565]
)
df = pd.DataFrame (gdp_cal, columns = ['Oil_Price', 'GDP_growth'])
udskrive (df)
df.plot (x = 'Oil_Price', y = 'GDP_growth', kind = 'scatter', color = 'red')
plt.at vise()
Linjekortplanlægning i Pandas
Linjediagrammet er en grundlæggende plottetype, hvor given information vises i en datapunktserie, der yderligere er forbundet med segmenter af lige linjer. Ved hjælp af linjediagrammerne kan du også vise tendenser for informationsoverarbejde.
Eksempel
I nedenstående eksempel har vi taget data om det forløbne års inflation. Forbered først dataene, og opret derefter DataFrame. Følgende kildekode tegner linjediagrammet for de tilgængelige data:
importer pandaer som pdimporter matplotlib.pyplot som plt
infl_cal = 'År': [2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011],
'Infl_Rate': [5.8, 10, 7, 6.7, 6.8, 6, 5.5, 8.2, 8.5, 9, 10]
data_frame = pd.DataFrame (infl_cal, columns = ['Year', 'Infl_Rate'])
data_frame.plot (x = 'År', y = 'Infl_Rate', kind = 'line')
plt.at vise()
I eksemplet ovenfor skal du indstille kind = 'line' til linjediagramplanlægning.
Metode 2 # Brug af plot.line () metode
Ovenstående eksempel kan du også implementere ved hjælp af følgende metode:
importer pandaer som pdimporter matplotlib.pyplot som plt
inf_cal = 'År': [2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011],
'Inflation_Rate': [5.8, 10, 7, 6.7, 6.8, 6, 5.5, 8.2, 8.5, 9, 10]
data_frame = pd.DataFrame (inf_cal, columns = ['Inflation_Rate'], index = [2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011])
dataramme.grund.linje ()
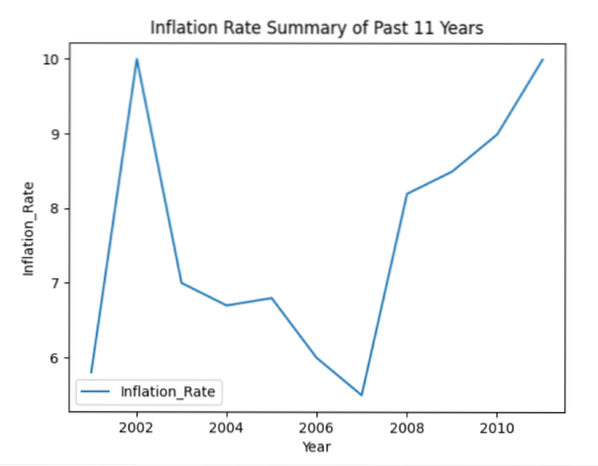
plt.titel ('Resumé af inflationen over de seneste 11 år')
plt.ylabel ('Inflation_Rate')
plt.xlabel ('År')
plt.at vise()
Følgende linjediagram vises efter kørsel af ovenstående kode:
Søjlediagramplanlægning i pandaer
Søjlediagramplotning bruges til at repræsentere de kategoriske data. I denne type plot er de rektangulære stænger med forskellige højder afbildet baseret på den givne information. Søjlediagrammet kan tegnes i to forskellige vandrette eller lodrette retninger.
Eksempel
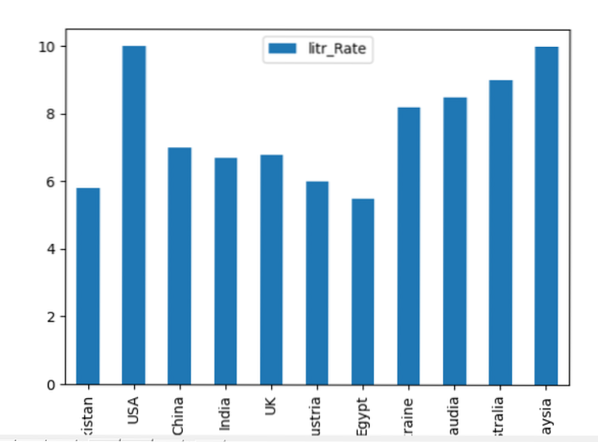
Vi har taget læsefærdighedsgraden i flere lande i det følgende eksempel. DataFrames oprettes, hvor 'Country_Names' og 'literacy_Rate' er de to kolonner i en DataFrame. Ved hjælp af Pandas kan du plotte oplysningerne i søjlediagramformen som følger:
importer pandaer som pdimporter matplotlib.pyplot som plt
lit_cal =
'Country_Names': ['Pakistan', 'USA', 'China', 'India', 'UK', 'Austria', 'Egypt', 'Ukraine', 'Saudia', 'Australia',
'Malaysia'],
'litr_Rate': [5.8, 10, 7, 6.7, 6.8, 6, 5.5, 8.2, 8.5, 9, 10]
data_frame = pd.DataFrame (lit_cal, columns = ['Country_Names', 'litr_Rate'])
udskrive (data_frame)
data_frame.grund.bar (x = 'Country_Names', y = 'litr_Rate')
plt.at vise()
Du kan også implementere ovenstående eksempel ved hjælp af følgende metode. Indstil kind = "bar" til stregdiagramplanlægning i denne linje:
dataramme.plot (x = 'Country_Names', y = 'litr_Rate', kind = 'bar')plt.at vise()
Vandret stregdiagramplanlægning
Du kan også plotte dataene på vandrette bjælker ved at udføre følgende kode:
importer matplotlib.pyplot som pltimporter pandaer som pd
data_chart = 'litr_Rate': [5.8, 10, 7, 6.7, 6.8, 6, 5.5, 8.2, 8.5, 9, 10]
df = pd.DataFrame (data_chart, columns = ['litr_Rate'], index = ['Pakistan', 'USA', 'China', 'India', 'UK', 'Austria', 'Egypt', 'Ukraine', 'Saudia' , 'Australien',
'Malaysia'])
df.grund.barh ()
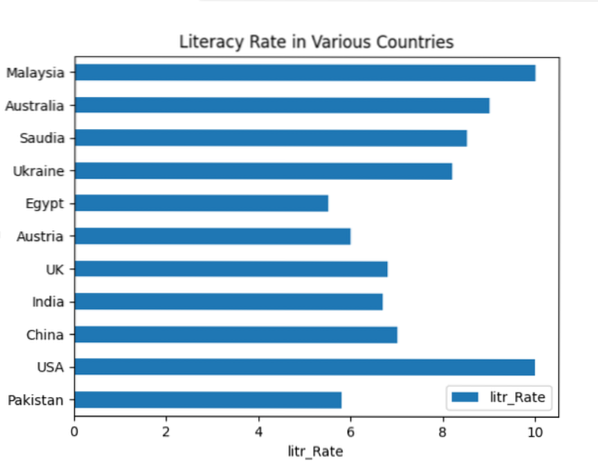
plt.titel ('Læsefærdighed i forskellige lande')
plt.ylabel ('Country_Names')
plt.xlabel ('litr_Rate')
plt.at vise()
I df.grund.barh (), bruges barh til vandret plotning. Efter kørsel af ovenstående kode vises følgende søjlediagram i vinduet:
Cirkeldiagram plotning i pandaer
Et cirkeldiagram repræsenterer dataene i en cirkulær grafisk form, hvor data vises i skiver baseret på den givne mængde.
Eksempel
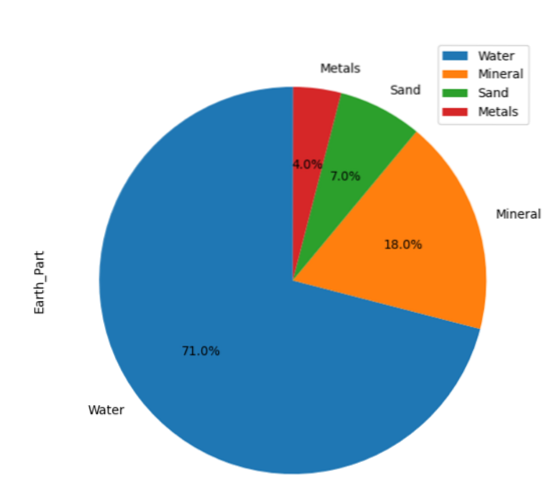
I det følgende eksempel har vi vist oplysningerne om 'Earth_material' i forskellige skiver på cirkeldiagrammet. Opret først DataFrame, og vis derefter alle detaljer på grafen ved hjælp af pandas.
importer pandaer som pdimporter matplotlib.pyplot som plt
material_per = 'Earth_Part': [71,18,7,4]
dataframe = pd.DataFrame (material_per, columns = ['Earth_Part'], index = ['Water', 'Mineral', 'Sand', 'Metals'])
dataframe.grund.pie (y = 'Earth_Part', figsize = (7, 7), autopct = '% 1.1f %% ', startangle = 90)
plt.at vise()
Ovenstående kildekode tegner cirkeldiagrammet over de tilgængelige data:
Konklusion
I denne artikel har du set, hvordan du plotter DataFrames i Pandas python. Forskellige former for plotning udføres i ovenstående artikel. At plotte flere slags som boks, hexbin, hist, kde, tæthed, areal osv., du kan bruge den samme kildekode bare ved at ændre plot-typen.


