Denne artikel viser dig, hvordan du finder duplikater i data og fjerner duplikater ved hjælp af Pandas Python-funktionerne.
I denne artikel har vi taget et datasæt over befolkningen i forskellige stater i USA, som er tilgængeligt i en .csv-filformat. Vi vil læse .csv-fil for at vise det originale indhold af denne fil som følger:
importer pandaer som pddf_state = pd.read_csv ("C: / Brugere / DELL / Desktop / population_ds.csv ")
udskrive (df_state)
I det følgende skærmbillede kan du se duplikatindholdet i denne fil:
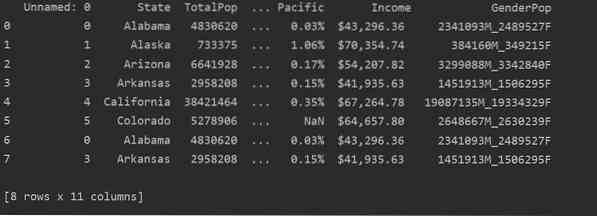
Identifikation af duplikater i Pandas Python
Det er nødvendigt at afgøre, om de data, du bruger, har duplikerede rækker. For at kontrollere for dataduplikering kan du bruge en hvilken som helst af metoderne, der er beskrevet i de følgende afsnit.
Metode 1:
Læs csv-filen, og send den til datarammen. Identificer derefter de dobbelte rækker ved hjælp af duplikeret () fungere. Endelig skal du bruge udskriftserklæringen til at vise de duplikerede rækker.
importer pandaer som pddf_state = pd.read_csv ("C: / Brugere / DELL / Desktop / population_ds.csv ")
Dup_Rows = df_state [df_state.duplikeret ()]
udskriv ("\ n \ nDubletterækker: \ n ".format (Dup_Rows))
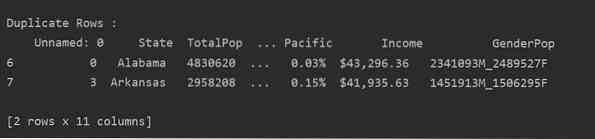
Metode 2:
Ved hjælp af denne metode, er_dubleret kolonne tilføjes i slutningen af tabellen og markeres som 'Sand' i tilfælde af duplikerede rækker.
importer pandaer som pddf_state = pd.read_csv ("C: / Brugere / DELL / Desktop / population_ds.csv ")
df_state ["is_duplicate"] = df_state.duplikeret ()
udskriv ("\ n ".format (df_state))
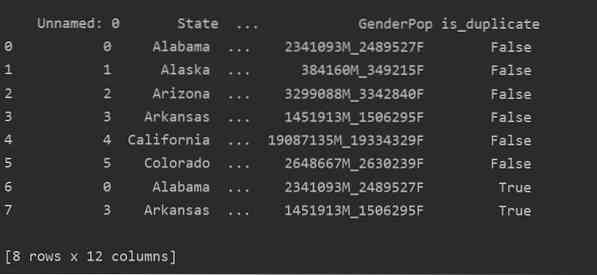
Dropping duplikater i Pandas Python
Dupliserede rækker kan fjernes fra din dataramme ved hjælp af følgende syntaks:
drop_duplicates (subset = ", keep =", inplace = False)
Ovenstående tre parametre er valgfri og forklares mere detaljeret nedenfor:
holde: denne parameter har tre forskellige værdier: Første, Sidste og Falsk. Den første værdi beholder den første forekomst og fjerner efterfølgende duplikater, den sidste værdi holder kun den sidste forekomst og fjerner alle tidligere duplikater, og den falske værdi fjerner alle duplikerede rækker.
delmængde: etiket, der bruges til at identificere de duplikerede rækker
på plads: indeholder to betingelser: Sandt og falsk. Denne parameter fjerner duplikerede rækker, hvis den er indstillet til Sand.
Fjern duplikater, der kun holder den første forekomst
Når du bruger "keep = first", bevares kun den første rækkeforekomst, og alle andre duplikater fjernes.
Eksempel
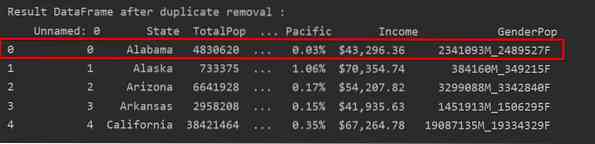
I dette eksempel bevares kun den første række, og de resterende duplikater slettes:
importer pandaer som pddf_state = pd.read_csv ("C: / Brugere / DELL / Desktop / population_ds.csv ")
Dup_Rows = df_state [df_state.duplikeret ()]
udskriv ("\ n \ nDubletterækker: \ n ".format (Dup_Rows))
DF_RM_DUP = df_stat.drop_duplicates (keep = 'first')
print ('\ n \ nResult DataFrame efter duplikat fjernelse: \ n', DF_RM_DUP.hoved (n = 5))
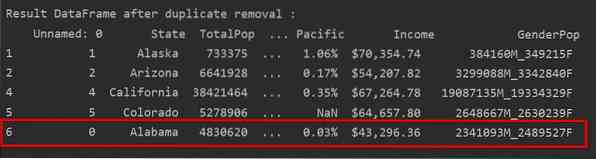
I det følgende skærmbillede er den bevarede forekomst af første række fremhævet med rødt, og de resterende duplikationer fjernes:
Fjern duplikater, der kun holder den sidste forekomst
Når du bruger "keep = last", fjernes alle duplikerede rækker undtagen den sidste forekomst.
Eksempel
I det følgende eksempel fjernes alle duplikerede rækker undtagen kun den sidste forekomst.
importer pandaer som pddf_state = pd.read_csv ("C: / Brugere / DELL / Desktop / population_ds.csv ")
Dup_Rows = df_state [df_state.duplikeret ()]
udskriv ("\ n \ nDubletterækker: \ n ".format (Dup_Rows))
DF_RM_DUP = df_stat.drop_duplicates (keep = 'last')
print ('\ n \ nResult DataFrame efter duplikat fjernelse: \ n', DF_RM_DUP.hoved (n = 5))
I det følgende billede fjernes dubletterne, og kun den sidste rækkeforekomst bevares:
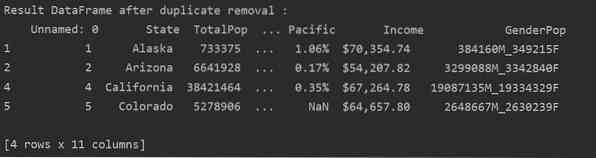
Fjern alle duplikerede rækker
For at fjerne alle duplikerede rækker fra en tabel skal du indstille "keep = False" som følger:
importer pandaer som pddf_state = pd.read_csv ("C: / Brugere / DELL / Desktop / population_ds.csv ")
Dup_Rows = df_state [df_state.duplikeret ()]
udskriv ("\ n \ nDubletterækker: \ n ".format (Dup_Rows))
DF_RM_DUP = df_stat.drop_duplicates (keep = False)
print ('\ n \ nResult DataFrame efter duplikat fjernelse: \ n', DF_RM_DUP.hoved (n = 5))
Som du kan se på det følgende billede, fjernes alle dubletter fra datarammen:
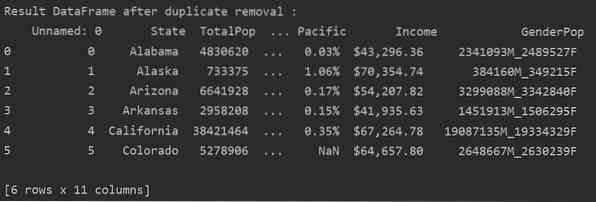
Fjern relaterede duplikater fra en specificeret kolonne
Som standard kontrollerer funktionen for alle duplikerede rækker fra alle kolonnerne i den givne dataramme. Men du kan også angive kolonnenavnet ved hjælp af delsætparameteren.
Eksempel
I det følgende eksempel fjernes alle relaterede dubletter fra kolonnen 'Stater'.
importer pandaer som pddf_state = pd.read_csv ("C: / Brugere / DELL / Desktop / population_ds.csv ")
Dup_Rows = df_state [df_state.duplikeret ()]
udskriv ("\ n \ nDubletterækker: \ n ".format (Dup_Rows))
DF_RM_DUP = df_stat.drop_duplicates (subset = 'State')
print ('\ n \ nResult DataFrame efter duplikat fjernelse: \ n', DF_RM_DUP.hoved (n = 6))
Konklusion
Denne artikel viste dig, hvordan du fjerner duplikerede rækker fra en dataramme ved hjælp af drop_duplicates () funktion i Pandas Python. Du kan også rydde dine data for duplikering eller redundans ved hjælp af denne funktion. Artiklen viste dig også, hvordan du identificerer eventuelle duplikater i din dataramme.


